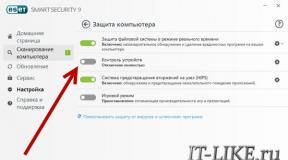
Нейронные сети в statistica пример. STATISTICA Automated Neural Networks (Автоматизированные нейронные сети). Нейронные сети STATISTICA Neural Networks: Методология и технология современного анализа данных
В чем же заключается сходство и различие языков нейрокомпьютинга и статистики в анализе данных. Рассмотрим простейший пример.
Предположим, что мы провели наблюдения и экспериментально измерили N пар точек, представляющих функциональную зависимость. Если попытаться провести через эти точки наилучшую прямую, что на языке статистики будет означать использование для описания неизвестной зависимости линейной модели
(где обозначает шум при проведении наблюдения), то решение соответствующей проблемы линейной регрессии сведется к нахождению оценочных значений параметров, минимизирующих сумму квадратичных невязок .
Если параметры и найдены, то можно оценить значение y длялюбого значения x, то есть осуществить интерполяцию и экстраполяцию данных.
Та же самая задача может быть решена с использованием однослойной сети с единственным входным и единственным линейным выходным нейроном. Вес связи a и порог b могут быть получены путем минимизации той же величины невязки (которая в данном случае будет называться среднеквадратичной ошибкой ) в ходе обучения сети, например методом backpropagation. Свойство нейронной сети к обобщению будет при этом использоваться для предсказания выходной величины по значению входа.
Рисунок 25. Линейная регрессия и реализующий ее однослойный персептрон.
При сравнении этих двух подходов сразу бросается в глаза то, что при описании своих методов статистика апеллирует к формулам и уравнениям , а нейрокомпьютинг к графическому описанию нейронных архитектур .
1 Если вспомнить, что с формулами и уравнениями оперирует левое полушарие, а с графическими образами правое, то можно понять, что в сопоставлении со статистикой вновь проявляется “правополушарность ” нейросетевого подхода.
Еще одним существенным различием является то, что для методов статистики не имеет значения, каким образом будет минимизироваться невязка - в любом случае модель остается той же самой, в то время как для нейрокомпьютинга главную роль играет именно метод обучения. Иными словами, в отличие от нейросетевого подхода, оценка параметров модели для статистических методов не зависит от метода минимизации. В то же время статистики будут рассматривать изменения вида невязки, скажем на
как фундаментальное изменение модели .
В отличие от нейросетевого подхода, в котором основное время забирает обучение сетей, при статистическом подходе это время тратится на тщательный анализ задачи. При этом опыт статистиков используется для выбора модели на основе анализа данных и информации, специфичной для данной области. Использование нейронных сетей - этих универсальных аппроксиматоров - обычно проводится без использования априорных знаний, хотя в ряде случаев оно весьма полезно. Например, для рассматриваемой линейной модели использование именно среднеквадратичной ошибки ведет к получению оптимальной оценки ее параметров, когда величина шума имеет нормальное распределение с одинаковой дисперсией для всех обучающих пар. В то же время если известно, что эти дисперсии различны, то использование взвешенной функции ошибки
может дать значительно лучшие значения параметров.
Помимо рассмотренной простейшей модели можно привести примеры других в некотором смысле эквивалентных моделей статистики и нейросетевых парадигм
Таблица 3. Аналогичные методики
Сеть Хопфилда имеет очевидную связь с кластеризацией данных и их факторным анализом.
1 Факторный анализ используется для изучения структуры данных. Основной его посылкой является предположение о существовании таких признаков - факторов , которые невозможно наблюдать непосредственно, но можно оценить по нескольким наблюдаемым первичным признакам. Так, например, такие признаки, как объем производства и стоимость основных фондов , могут определять такой фактор, как масштаб производства . В отличие от нейронных сетей, требующих обучения, факторный анализ может работать лишь с определенным числом наблюдений. Хотя в принципе число таких наблюдений должно лишь на единицу превосходить число переменных рекомендуется использовать хотя бы втрое большее число значение. Это все равно считается меньшим, чем объем обучающей выборки для нейронной сети. Поэтому статистики указывают на преимущество факторного анализа, заключающееся в использовании меньшего числа данных и, следовательно, приводящего к более быстрой генерации модели. Кроме того, это означает, что реализация методов факторного анализа требует менее мощных вычислительных средств. Другим преимуществом факторного анализа считается то, что он является методом типа white-box, т.е. полностью открыт и понятен - пользователь может легко осознавать, почему модель дает тот или иной результат. Связь факторного анализа с моделью Хопфилда можно увидеть, вспомнив векторы минимального базиса для набора наблюдений (образов памяти - см. Главу 5). Именно эти векторы являются аналогами факторов, объединяющих различные компоненты векторов памяти - первичные признаки.
1 Логистическая регрессия является методом бинарной классификации, широко применяемом при принятии решений в финансовой сфере. Она позволяет оценивать вероятность реализации (или нереализации) некоторого события в зависимости от значений некоторых независимых переменных - предикторов: x 1 ,...,x N . В модели логистической регресии такая вероятность имеет аналитическую форму: Pr(X ) =(1+exp(-z)) -1 , где z = a 0 + a 1 x 1 +...+ a N x N . Нейросетевым аналогом ее, очевидно, является однослойный персептрон с нелинейным выходным нейроном. В финансовых приложениях логистическую регрессию по ряду причин предпочитают многопараметрической линейной регрессии и дискриминантному анализу. В частности, она автоматически обеспечивает принадлежность вероятности интервалу , накладывает меньше ограничений на распределение значений предикторов. Последнее очень существенно, поскольку распределение значений финансовых показателей, имеющих форму отношений, обычно не является нормальным и “сильно перекошено”. Достоинством нейронных сетей является то, что такая ситуация не представляет для них проблемы. Кроме того, нейросети нечувствительны к корреляции значений предикторов, в то время как методы оценки параметров регрессионной модели в этом случае часто дают неточные значения.
R - это свободная программная среда для статистических вычислений и графиков.
Это проект GNU, похожий на язык и среду S, который был разработан в Bell Laboratories (ранее AT & T, сейчас Lucent Technologies) Джоном Чамберсом и его коллегами. R может рассматриваться как другая реализация S. Есть некоторые важные различия, но большая часть кода, написанного для S, работает без изменений под R
Бесплатная Открытый код Mac Windows Linux BSD
RStudio
RStudio ™ - это интегрированная среда разработки (IDE) для языка программирования R. RStudio сочетает в себе интуитивно понятный пользовательский интерфейс и мощные инструменты кодирования, которые помогут вам максимально использовать возможности R.
Бесплатная Открытый код Mac Windows Linux Xfce
PSPP
PSPP - это бесплатное программное приложение для анализа выборочных данных. Оно имеет графический интерфейс пользователя и обычный интерфейс командной строки. Он написан на C, использует научную библиотеку GNU для своих математических процедур и plotutils для генерации графов. Он предназначен для бесплатной замены проприетарной программы SPSS.
Бесплатная Открытый код Mac Windows Linux
IBM SPSS Statistics
Программная платформа IBM SPSS предлагает расширенный статистический анализ, обширную библиотеку алгоритмов машинного обучения, анализ текста, расширяемость с открытым исходным кодом, интеграцию с большими данными и плавное развертывание в приложениях.
Платная Mac Windows Linux
SOFA Statistics
SOFA Statistics - это статистический пакет с открытым исходным кодом, в котором особое внимание уделяется простоте использования, обучению по ходу работы и прекрасным результатам. Название расшифровывается как «Статистика, открытая для всех». Он имеет графический интерфейс пользователя и может напрямую подключаться к MySQL, SQLite, MS Access и MS SQL Server
Бесплатная Открытый код Mac Windows Linux
Что в этом списке?
В списке находится программы которые можно использовать для замены STATISTICA на платформах Windows. Этот список содержит 6 приложений, похожих на STATISTICA.
Обширную тему решил затронуть. Искусственные нейронные сети. Попытаюсь дать представление на пальцах. Что это такое? Это попытка смоделировать человеческий мозг. Только более примитивно. Базовым элементом каждой нейронной сети является нейрон (Рис. 1).
Рис. 1. Принципиальная схема нейрона.
Нейрон имеет входы, сумматор и функцию активации. На входы подается информация, например содержание трех хим. элементов в конкретной пробе. Каждое из них умножается на определенный коэффицициент. Далее входящие сигналы суммируются и преобразуются с помощью активационной функции. Это может быть тангенс данного числа, или e^(-1*данную сумму), где е – число Эйлера. Весь цимес заключается в:
Весах нейронов;
Функции активации;
Наборе нейронов. Если взять несколько нейронов и организовать их в слои, в каждом из которых будет от 1 до N нейронов, то это будет искуссвенная нейронная сеть.
Искусственные нейронные сети необходимо обучать, или дать им возможность самообучится. Обучить нейронную сеть – означает дать ей выборку и подстроить веса так, что бы нейроны максимально точно описывали данные. Функции активации как раз моделируют нелинейные взаимосвязи хим. элементов. А структура нейронной сети (количество нейронов, количество слоев) контролирует гибкость сети. То насколько точно она может подстроится под данные. При этом в геохимии совсем точная подстройка не нужна. Важно выявить закономерности.
Когда нам мало чего известно о данных используется кластеризация. В случае нейронных сетей используются самообучающиеся нейронные сети Кохонена. Смысл их заключается в том, что нейроны как на рисунке 1, организуются в один двумерный слой(Рис. 2). Нейронам сначала случайным образом задаются первичные веса, и подаются наблюдения. Нейроны соревнуются между собой, кто лучше опишет наблюдение. Победители пытаются подстроить своих соседей. В конечном счете, когда в данных находятся реальные кластеры, они будут описаны разными группами нейронов. Прелесть, да?

Рис. 2. Принципиальная схема Самоорганизующейся сети Кохонена. 4х3 нейрона = 12 нейронов.
 Рис. 3. Открываем данные и запускаем модуль нейросетевого анализа. Данные можно использовать сырые, без предварительного логарифмирования. Но явные выбросы все равно лучше убрать.
Рис. 3. Открываем данные и запускаем модуль нейросетевого анализа. Данные можно использовать сырые, без предварительного логарифмирования. Но явные выбросы все равно лучше убрать.
 Рис. 4 Выбираем кластерный анализ
Рис. 4 Выбираем кластерный анализ
 Рис. 5. Выбираем переменные во вкладке Quick (Быстро). В данном модуле можно выбрать категориальные входные переменные. Например, возраст пород из которых отобрана проба.
Рис. 5. Выбираем переменные во вкладке Quick (Быстро). В данном модуле можно выбрать категориальные входные переменные. Например, возраст пород из которых отобрана проба.
 Рис. 6 Переходим во вторую вкладку Sampling (Подвыборки). Нейронные сети разбивают первоначальную выборку на три подвыборки:
Рис. 6 Переходим во вторую вкладку Sampling (Подвыборки). Нейронные сети разбивают первоначальную выборку на три подвыборки:
Обучающую. По ней производится обучение нейронной сети и подстройка весов;
Тестовую. Она так же используется в процессе обучения и проверяет не переробучилась ли сеть;
Проверочная выборка. Она не используется в процессе обучения, а служит лишь для оценки точности сети на “новых” данных. То есть ее возможность предсказания.
Оставим по умолчанию. Жмем ОК.
 Рис. 7 Во вкладке Quick (Kohonen), задаем количество нейронов и их структуру. Поскольку нейроны обучают соседей, то расположение нейронов тоже важно. Либо 4 нейрона расположить квадратом, либо цепочкой. Для начала выбираем 5х5. Не стремитесь сделать огромные сети. Помните, что важно выявить общие закономерности, а не сразу все-все решить.
Рис. 7 Во вкладке Quick (Kohonen), задаем количество нейронов и их структуру. Поскольку нейроны обучают соседей, то расположение нейронов тоже важно. Либо 4 нейрона расположить квадратом, либо цепочкой. Для начала выбираем 5х5. Не стремитесь сделать огромные сети. Помните, что важно выявить общие закономерности, а не сразу все-все решить.
 Рис. Во вкладке Kohonen Training (Обучение сети) самый важный параметр Neighborhoods (Соседи) – то сколько соседей обучает нейрон. Оставим по умолчанию. Жмем ОК.
Рис. Во вкладке Kohonen Training (Обучение сети) самый важный параметр Neighborhoods (Соседи) – то сколько соседей обучает нейрон. Оставим по умолчанию. Жмем ОК.
 Рис. 9. Сеть обучается и выводится окно результатов. Сразу переходим во вкладку Kohonen (graph). Тут показывается все 25 нейронов и то какое количество обучающих проб попало в каждый. Считается необходимым, что бы каждый нейрон описал какую-то часть данных. Не должно быть пустых нейронов. Пики представленные бурым красным цветом показывают сколько проб описал данный нейрон. В целом, тут выделяются три пика. Скорее всего у нас три кластера. Жмем Cancel, Cancel и переходим в первую вкладку выбора структуры сети.
Рис. 9. Сеть обучается и выводится окно результатов. Сразу переходим во вкладку Kohonen (graph). Тут показывается все 25 нейронов и то какое количество обучающих проб попало в каждый. Считается необходимым, что бы каждый нейрон описал какую-то часть данных. Не должно быть пустых нейронов. Пики представленные бурым красным цветом показывают сколько проб описал данный нейрон. В целом, тут выделяются три пика. Скорее всего у нас три кластера. Жмем Cancel, Cancel и переходим в первую вкладку выбора структуры сети.
 Рис. 10. Выбираем цепочку нейронов из трех штук. Каждый нейрон опишет свой кластер.
Рис. 10. Выбираем цепочку нейронов из трех штук. Каждый нейрон опишет свой кластер.
 Рис. 11. Перейдем во вкладку Обучение сети и выберем, что бы каждый нейрон влиял только на одного соседа. Связанные кластеры получатся. Тут стоит поэксперементировать. Если влияние на соседей, то врядли получится уловить переходные области.
Рис. 11. Перейдем во вкладку Обучение сети и выберем, что бы каждый нейрон влиял только на одного соседа. Связанные кластеры получатся. Тут стоит поэксперементировать. Если влияние на соседей, то врядли получится уловить переходные области.
 Рис. 12. Получаем результат. Каждый нейрон описал изрядное количество данных.
Рис. 12. Получаем результат. Каждый нейрон описал изрядное количество данных.
 Рис. 13. Перейдем в первую вкладку окна результатов Predictions (Предсказание). Выведем результаты по каждой пробе с координатами.
Рис. 13. Перейдем в первую вкладку окна результатов Predictions (Предсказание). Выведем результаты по каждой пробе с координатами.
 Рис. 14. Получаем выходную табличку. Что бы построить график из данных в ней, необходимо сделать табличку активной. Выделяем, щелкаем правой клавишей мышки и выбираем пункт Active Input
(Активный Ввод). Тут как и в методе k-средних имеется столбец с “расстоянием” пробы до кластера (нейрона). Чем меньше число, тем лучше. Если число очень высокое, то это либо выброс, либо совсем отдельный кластер.
Рис. 14. Получаем выходную табличку. Что бы построить график из данных в ней, необходимо сделать табличку активной. Выделяем, щелкаем правой клавишей мышки и выбираем пункт Active Input
(Активный Ввод). Тут как и в методе k-средних имеется столбец с “расстоянием” пробы до кластера (нейрона). Чем меньше число, тем лучше. Если число очень высокое, то это либо выброс, либо совсем отдельный кластер.
 Рис. 15. Строим карту кластеров. Об этом можете . Конечно эти графики лучше строить в ArcGIS или в Surfer. Делать описание с учетом геол.карты. К сожалению тут я не могу много об этом писать. Но скажу лишь то, что кластеризация нейронной сетью выдала аналогичный результат, что и Иерархическая кластеризация и k-средних. Далее можно построить графики типа Ящик-с –усами и дать заключение о специализации кластеров. Поскольку эту выборку я кластеризую уже в третий раз, то не привожу их. Смотрите предыдущие посты.
Рис. 15. Строим карту кластеров. Об этом можете . Конечно эти графики лучше строить в ArcGIS или в Surfer. Делать описание с учетом геол.карты. К сожалению тут я не могу много об этом писать. Но скажу лишь то, что кластеризация нейронной сетью выдала аналогичный результат, что и Иерархическая кластеризация и k-средних. Далее можно построить графики типа Ящик-с –усами и дать заключение о специализации кластеров. Поскольку эту выборку я кластеризую уже в третий раз, то не привожу их. Смотрите предыдущие посты.
Дополнительно построим карту значений активации. Значение активации – это как раз там сумма элементов преобразованная нелинейной функцией.
 Рис. 16. Карта распределения значений активации наблюдений. На юге площади выделяется группа проб с высокими значениями активации. Стоит отдельно рассмотреть их по моноэлементным картам и другим параметрам.
Рис. 16. Карта распределения значений активации наблюдений. На юге площади выделяется группа проб с высокими значениями активации. Стоит отдельно рассмотреть их по моноэлементным картам и другим параметрам.
 Рис. 17. Сохраняем структуру нейронной сети. Что бы всегда можно было к ней вернутся.
Рис. 17. Сохраняем структуру нейронной сети. Что бы всегда можно было к ней вернутся.
 Рис. 18. Когда запускам модуль нейросетевого анализа, слева находится окно в котором можно открыть уже созданную нейронную сеть. Например, вы изучили эталонный объект, создали по нему нейронную сеть и хотите прогнать через нее пробы с другой площади. Вуаля.
Рис. 18. Когда запускам модуль нейросетевого анализа, слева находится окно в котором можно открыть уже созданную нейронную сеть. Например, вы изучили эталонный объект, создали по нему нейронную сеть и хотите прогнать через нее пробы с другой площади. Вуаля.
- Хайкин Саймон Нейронные сети: полный курс, 2-е издание. : Пер. с англ. – М. : Издательский дом “Вильямс”, 2006. – 1104 с. : ил. – Парал. тит. англ. ISBN 5-8459-0890-6 (рус)
- Нейронные сети. STATISTICA Neural Networks: Методология и технология современного анализа данных/ Под редакцией В.П. Боровикова. – 2-е изд., перераб. и доп. – М.: Горячая линия – Телеком, 2008. – 292 с., ил. ISBN 978-5-9912-0015-8
Вторая книга отличается от модуля в Statistica 10, но тоже подойдет.
STATISTICA Automated Neural Networks - единственный в мире нейросетевой программный продукт, полностью переведенный на русский язык!
Методологии нейронных сетей получают все большее распространение в самых различных областях деятельности от фундаментальных исследований до практических приложений анализа данных, бизнеса, промышленности и др.
является одним из самых передовых и самых эффективных нейросетевых продуктов на рынке. Он предлагает множество уникальных преимуществ и богатых возможностей. Например, уникальные возможности инструмента автоматического нейросетевого поиска, , позволяют использовать систему не только экспертам по нейронным сетям, но и новичкам в области нейросетевых вычислений.
В чем преимущества использования ?
Пре- и пост-процессирование, включая выбор данных, кодирование номинальных значений, шкалирование, нормализацию, удаление пропущенных данных с интерпретацией для классификации, регрессию и задачи временных рядов;
Исключительная простота в использовании плюс непревзойденная аналитическая мощность; так, например, не имеющий аналогов инструмент автоматического нейросетевого поиска Автоматизированная нейронная сеть (АНС) проведет пользователя через все этапы создания различных нейронных сетей и выберет наилучшую (в противном случае эта задача решается длительным путем "проб и ошибок" и требует серьезного знания теории);
Самые современные, оптимизированные и мощные алгоритмы обучения сети (включая методы сопряженных градиентов, алгоритм Левенберга-Марквардта, BFGS, алгоритм Кохонена); полный контроль над всеми параметрами, влияющими на качество сети, такими как функции активации и ошибок, сложность сети;
Поддержка ансамблей нейросетей и нейросетевых архитектур практически неограниченного размера;
Богатые графические и статистические возможности, которые облегчают интерактивный исследовательский анализ;
Полная интеграция с системой STATISTICA ; все результаты, графики, отчеты и т. д. могут быть в дальнейшем модифицированы с помощью мощных графических и аналитических инструментов STATISTICA (например, для проведения анализа предсказанных остатков, создания подробного отчета и т. п.);
Полная интеграция с мощными автоматическими инструментами STATISTICA ; запись полноценных макросов для любых анализов; создание собственных нейросетевых анализов и приложений с помощью STATISTICA Visual Basic, вызов STATISTICA Automated Neural Networks из любого приложения, поддерживающего технологию СОМ (например, автоматическое проведение нейросетевого анализа в таблице MS Excel или объединение нескольких пользовательских приложений, написанных на языках C, С++, С#, Java и т. д.).
- Выбор наиболее популярных сетевых архитектур, включая Многослойные персептроны, Радиальные базисные функции и Самоорганизующиеся карты признаков.
- Имеется инструмент Автоматического Сетевого Поиска , позволяющий в автоматическом режиме строить различные нейросетевые архитектуры и регулировать их сложность.
- Сохранение наилучших нейронных сетей.
- Опциональная возможность генерации исходного кода на языках C, C++, C#, Java, PMML (Predictive Model Markup Language), который может быть легко интегрирован во внешнюю среду для создания собственных приложений.
Поддержка различного рода статистического анализа и построение прогнозирующих моделей, включая регрессию, классификацию, временные ряды с непрерывной и категориальной зависимой переменной, кластерный анализ для снижения размерности и визуализации.
Поддержка загрузки и анализа нескольких моделей.
Генератор кода
Генератор кода STATISTICA Автоматизированные Нейронные Сети может сгенерировать исходный системный программный код нейросетевых моделей на языках C, Java и PMML (Predictive Model Markup Language). Генератор кода является дополнительным приложением к системе STATISTICA Автоматизированные Нейронные Сети , которое позволяет пользователям на основе проведенного нейросетевого анализа генерировать C или Java-файл с исходным кодом моделей и интегрировать его в независимые внешние приложения.
Генератор кода требует наличия STATISTICA Автоматизированные Нейронные Сети .
Генерирует версию исходного кода нейронной сети (в виде файла на языке C, C++, C# или Java).
C или Java-файл с кодом можно затем встроить во внешние программы.
STATISTICA Automated Neural Networks в нейросетевых вычислениях
Использование нейронных сетей подразумевает гораздо большее, чем просто обработку данных нейросетевыми методами.

STATISTICA Automated Neural Networks (SANN) предоставляет разнообразные функциональные возможности, для работы с очень сложными задачами, включающие не только новейшие Архитектуры Нейронных Сетей и Алгоритмы обучения , но также и новые подходы к построению нейросетевых архитектур с возможностью перебора различных функций активаций и ошибок, что позволяет проще интерпретировать результаты. Кроме того, разработчики программного обеспечения и пользователи, экспериментирующие с настройками приложений, оценят тот факт, что после проведения заданных экспериментов в простом и интуитивно понятном интерфейсе STATISTICA Automated Neural Networks (SANN) , нейросетевые анализы могут быть объединены в пользовательском приложении. Это достигается либо с помощью библиотеки СОМ-функций STATISTICA , которая полностью отражает все функциональные возможности программы, либо с помощью кода на языке C/C++, который генерируется программой и помогает запустить полностью обученную нейронную сеть.
 Модуль STATISTICA Automated Neural Networks
полностью интегрирован с системой STATISTICA
, таким образом доступен огромный выбор инструментов редактирования (подготовки) данных для анализа (преобразования, условия выбора наблюдений, средства проверки данных и т. д.).
Модуль STATISTICA Automated Neural Networks
полностью интегрирован с системой STATISTICA
, таким образом доступен огромный выбор инструментов редактирования (подготовки) данных для анализа (преобразования, условия выбора наблюдений, средства проверки данных и т. д.).
Как и все анализы STATISTICA , программа может быть "присоединена" к удаленной базе данных с помощью инструментов обработки "на месте" или связана с активными данными, чтобы модели обучались или запускались (например, для вычисления предсказанных значений или классификации) автоматически каждый раз при изменении данных.
Шкалирование данных и преобразование номинальных значений
Перед тем, как данные будут введены в сеть, они должны быть определенным образом подготовлены. Столь же важно, чтобы выходные данные можно было правильно интерпретировать. В STATISTICA Automated Neural Networks (SANN) имеется возможность автоматического масштабирования входных и выходных данных; также могут быть автоматически перекодированы переменные с номинальными значениями (например, Пол={Муж,Жен}), в том числе по методу 1-из-N кодирования. STATISTICA Automated Neural Networks (SANN) содержит также средства работы с пропущенными данными. Имеются средства подготовки и интерпретации данных, специально предназначенные для анализа временных рядов. Большое разнообразие аналогичных средств реализовано также в STATISTICA .
В задачах классификации имеется возможность установить доверительные интервалы, которые STATISTICA Automated Neural Networks (SANN) использует затем для отнесения наблюдений к тому или иному классу. В сочетании со специальной реализованной в STATISTICA Automated Neural Networks (SANN) функцией активации Софтмакс и кросс-энтропийными функциями ошибок это дает принципиальный теоретико-вероятностный подход к задачам классификации.
Выбор нейросетевой модели, ансамбли нейронных сетей
Многообразие моделей нейронных сетей и множество параметров, которые необходимо установить (размеры сети, параметры алгоритма обучения и т. д.), может поставить иного пользователя в тупик. Но для этого и существует инструмент автоматического нейросетевого поиска, , который может автоматически провести поиск подходящей архитектуры сети любой сложности, см. ниже. В системе STATISTICA Automated Neural Networks (SANN)
реализованы все основные типы нейронных сетей, используемые при решении практических задач, в том числе: 
многослойные персептроны (сети с прямой передачей сигнала);
сети на радиальных базисных функциях;
самоорганизующиеся карты Кохонена.
Приведенные выше архитектуры используются в задачах регрессии, классификации, временных рядах (с непрерывной или категориальной зависимой переменной) и кластеризации.
Кроме того, в системе STATISTICA Automated Neural Networks (SANN) реализованы Сетевые ансамбли , формируемые из случайных (но значимых) комбинаций вышеперечисленных сетей. Этот подход особенно полезен при зашумленных данных и данных небольшой размерности.
В пакете STATISTICA Automated Neural Networks (SANN) имеются многочисленные средства, облегчающие пользователю выбор подходящей архитектуры сети. Статистический и графический инструментарий системы включает гистограммы, матрицы и графики ошибок для всей совокупности и по отдельным наблюдениям, итоговые данные о правильной/неправильной классификации, а все важные статистики, например, объясненная доля дисперсии - вычисляются автоматически.
 Для визуализации данных в пакете STATISTICA Automated Neural Networks (SANN)
реализованы диаграммы рассеяния и трехмерные поверхности отклика, помогающие пользователю понять "поведение" сети.
Для визуализации данных в пакете STATISTICA Automated Neural Networks (SANN)
реализованы диаграммы рассеяния и трехмерные поверхности отклика, помогающие пользователю понять "поведение" сети.
Разумеется, любую информацию, полученную из перечисленных источников, Вы можете использовать для дальнейшего анализа другими средствами STATISTICA , а также для последующего включения в отчеты или для настройки.
STATISTICA Automated Neural Networks (SANN) автоматически запоминает лучший вариант сети из тех, которые Вы получали, экспериментируя над задачей, и Вы можете обратиться к нему в любой момент. Полезность сети и ее способность к прогнозированию автоматически проверяется на специальном проверочном множестве наблюдений, а также путем оценки размеров сети, ее эффективности и цены неправильной классификации. Реализованные в STATISTICA Automated Neural Networks (SANN) автоматические процедуры кросс-проверки и регуляризации весов позволяют Вам быстро выяснить, является ли Ваша сеть недостаточно или, наоборот, чересчур сложной для данной задачи.
Для улучшения производительности в пакете STATISTICA Automated Neural Networks представлены многочисленные опции настройки сети. Так, Вы можете задать линейный выходной слой сети в задачах регрессии или функцию активации типа софтмакс в задачах вероятностного оценивания и классификации. В системе также реализованы основанные на моделях теории информации кросс-энтропийные функции ошибок и ряд специальных функций активации, включающий Тождественную, Экспоненциальную, Гиперболическую, Логистическую (сигмоидная) и Синус функции как для скрытых, так и выходных нейронов.
Автоматизированная нейронная сеть (автоматический поиск и выбор различных нейросетевых архитектур)
 Составной частью пакета STATISTICA Automated Neural Networks (SANN)
является инструмент автоматического нейросетевого поиска, Автоматизированная нейронная сеть (АНС)
- Automated Network Search (ANS)
, который оценивает множество нейронных сетей различной архитектуры и сложности и выбирает сети наилучшей архитектуры для данной задачи.
Составной частью пакета STATISTICA Automated Neural Networks (SANN)
является инструмент автоматического нейросетевого поиска, Автоматизированная нейронная сеть (АНС)
- Automated Network Search (ANS)
, который оценивает множество нейронных сетей различной архитектуры и сложности и выбирает сети наилучшей архитектуры для данной задачи.
 Значительное время при создании нейронной сети уходит на выбор соответствующих переменных и оптимизацию архитектуры сети методом эвристического поиска. STATISTICA Automated Neural Networks (SANN)
берет эту работу на себя и автоматически проводит эвристический поиск за Вас. Эта процедура учитывает входную размерность, тип сети, размеры сети, функции активации и даже требуемые выходные функции ошибок.
Значительное время при создании нейронной сети уходит на выбор соответствующих переменных и оптимизацию архитектуры сети методом эвристического поиска. STATISTICA Automated Neural Networks (SANN)
берет эту работу на себя и автоматически проводит эвристический поиск за Вас. Эта процедура учитывает входную размерность, тип сети, размеры сети, функции активации и даже требуемые выходные функции ошибок.
Является чрезвычайно эффективным инструментом при использовании сложных техник, позволяя автоматически находить наилучшую архитектуру сети. Вместо того чтобы тратить многие часы на сидение перед компьютером, предоставьте системе STATISTICA Automated Neural Networks (SANN) сделать эту работу за Вас.
 Успех Ваших экспериментов по поиску наилучшего типа и архитектуры сети существенным образом зависит от качества и скорости алгоритмов обучения сети. В системе STATISTICA Automated Neural Networks (SANN)
реализованы самые лучшие на сегодняшний день обучающие алгоритмы.
Успех Ваших экспериментов по поиску наилучшего типа и архитектуры сети существенным образом зависит от качества и скорости алгоритмов обучения сети. В системе STATISTICA Automated Neural Networks (SANN)
реализованы самые лучшие на сегодняшний день обучающие алгоритмы.
В системе STATISTICA Automated Neural Networks (SANN) реализованы два быстрых алгоритма второго порядка - методы сопряженных градиентов и алгоритм BFGS. Последний представляет собой необычайно мощный современный алгоритм нелинейной оптимизации, и специалисты очень рекомендуют им пользоваться. Также имеется упрощенная версия алгоритма BFGS, требующая меньшего количества памяти, который используется системой в случае, когда возможности оперативной памяти компьютера достаточно ограничены. Эти алгоритмы, как правило, быстрее сходятся и получают более точное решение, чем алгоритмы первого порядка точности, например, Градиентный спуск.
Итеративный процесс обучения сети в системе STATISTICA Automated Neural Networks (SANN) сопровождается автоматическим отображением текущей ошибки обучения и вычисляемой независимо от нее ошибки на проверочном множестве, при этом показывается и график суммарной ошибки. Вы можете прервать обучение в любой момент, просто нажав кнопку. Кроме того, имеется возможность задать условия остановки, при выполнении которых обучение будет прервано; таким условием может быть, например, достижение определенного уровня ошибки, или стабильный рост проверочной ошибки на протяжении заданного числа проходов - "эпох" (что свидетельствует о так называемом переобучении сети). Если переобучение имеет место, это не должно заботить пользователя: STATISTICA Automated Neural Networks (SANN) автоматически запоминает экземпляр наилучшей сети, полученной в процессе обучения, и к этому варианту сети всегда можно обратиться, нажав соответствующую кнопку. После того, как обучение сети завершено, Вы можете проверить качество ее работы на отдельном тестовом множестве.
 После того, как сеть обучена, нужно проверить качество ее работы и определить характеристики. Для этого в пакете STATISTICA Automated Neural Networks (SANN)
имеется набор экранных статистик и графических средств.
После того, как сеть обучена, нужно проверить качество ее работы и определить характеристики. Для этого в пакете STATISTICA Automated Neural Networks (SANN)
имеется набор экранных статистик и графических средств.
В том случае, если заданы несколько моделей (сетей и ансамблей), то (если это возможно) STATISTICA Automated Neural Networks (SANN) отобразит сравнительные результаты (например, построит кривые отклика нескольких моделей на одном графике, или представит предикторы нескольких моделей в одной таблице). Это свойство очень полезно для сравнения различных моделей, обучаемых на одном наборе данных.
 Все статистики вычисляются раздельно для обучающего, проверочного и тестового множеств или в любой их совместной комбинации, на усмотрение пользователя.
Все статистики вычисляются раздельно для обучающего, проверочного и тестового множеств или в любой их совместной комбинации, на усмотрение пользователя.
Автоматически вычисляются следующие итоговые статистики: среднеквадратичная ошибка сети, так называемая матрица несоответствий (confusion matrix) для задач классификации (где суммируются все случаи правильной и неправильной классификации) и корреляции для задач регрессии. Сеть Кохонена имеет окно Топологической карты, в котором можно визуально наблюдать активации элементов сети.
Готовые решения (пользовательские приложения, использующие STATISTICA Automated Neural Networks )
Простой и удобный интерфейс системы STATISTICA Automated Neural Networks (SANN) позволяет Вам быстро создавать нейросетевые приложения для решения Ваших задач.
 Возможна такая ситуация, когда необходимо встроить эти решения в уже имеющуюся систему, например, сделать их частью более широкой вычислительной среды (это могут быть процедуры, разработанные отдельно и встроенные в корпоративную вычислительную систему).
Возможна такая ситуация, когда необходимо встроить эти решения в уже имеющуюся систему, например, сделать их частью более широкой вычислительной среды (это могут быть процедуры, разработанные отдельно и встроенные в корпоративную вычислительную систему).
Обученные нейронные сети могут быть применены к новым наборам данных (для предсказания) несколькими способами: Можно сохранить обученные сети и затем применить их к новому набору данных (для предсказания, классификации или прогнозирования); Можно использовать генератор кода для автоматического создания программного кода на языке С (С++, C#) или Visual Basic и в дальнейшем использовать его для предсказания новых данных в любой программной среде visual basic или С++ (C#), т. е. внедрить полностью обученную нейронную сеть в Ваше приложение. В заключение, все функциональные возможности системы STATISTICA , включая STATISTICA Automated Neural Networks (SANN) , могут быть использованы в качестве СОМ объектов (Component Object Model) в других приложениях (например, Java, MS Excel, C#, VB.NET и т. д.). Например, Вы можете внедрить автоматический анализ, созданный с помощью STATISTICA Automated Neural Networks (SANN) в таблицы MS Excel.
Перечень алгоритмов обучения
Градиентный спуск
Сопряженные градиенты
Обучение Кохонена
Метод k-средних для Сети радиальных базисных функций
Ограничения в размерах сетей
Нейронная сеть может быть практически любого размера (то есть ее размеры можно взять во много раз больше, чем это в действительности нужно и разумно); для сети многослойных персептронов допускается один скрытый слой нейронов. Фактически, для любых практических задач программа ограничена только аппаратными возможностями компьютера.
Электронное руководство
В составе системы STATISTICA Automated Neural Networks (SANN) имеется хорошо иллюстрированный учебник, содержащий полное и понятное введение в нейронные сети, а также примеры. Из любого диалогового окна доступна система подробных контекстно-зависимых справок.
Генератор исходного кода
Генератор исходного кода является дополнительным продуктом, который позволяет пользователям легко создавать собственные приложения на базе системы STATISTICA Automated Neural Networks (SANN) . Этот дополнительный продукт создает исходный системный код нейросетевой модели (в виде файла на языке C, C++, C# или Java), который можно отдельно скомпилировать и интегрировать в Вашу программу для свободного распространения. Этот продукт разработан специально для корпоративных системных разработчиков, а также тех пользователей, кому необходимо преобразовать высокооптимизированные процедуры, созданные в STATISTICA Automated Neural Networks (SANN) , во внешние приложения для решения сложных аналитических задач. (Необходимо отметить, что для получения разрешения, пользователи должны сообщить сотрудникам компании сайтssia о распространении программ, использующих сгенерированный код).