Erstellen eines Clusters aus 2 Computern. Desktop-Cluster
Entscheiden Sie zunächst, welche Komponenten und Ressourcen benötigt werden. Sie benötigen einen Master-Knoten, mindestens ein Dutzend identischer Rechenknoten, einen Ethernet-Switch, eine Stromverteilungseinheit und ein Rack. Bestimmen Sie den Verkabelungs- und Kühlungsaufwand sowie den Platzbedarf. Entscheiden Sie auch, welche IP-Adressen Sie für Knoten verwenden möchten, welche Software Sie installieren und welche Technologien erforderlich sind, um parallele Rechenleistung zu erzeugen (mehr dazu weiter unten).
- Obwohl die Hardware teuer ist, ist die gesamte Software in diesem Artikel kostenlos und das meiste davon Open Source.
- Wenn Sie wissen möchten, wie schnell Ihr Supercomputer theoretisch sein könnte, verwenden Sie dieses Tool:
Mounten Sie die Knoten. Sie müssen Hosts erstellen oder vorgefertigte Server kaufen.
- Wählen Sie Serverrahmen, die Platz und Energie am effizientesten nutzen und effizient kühlen.
- Oder Sie können etwa ein Dutzend gebrauchte Server "recyceln", einige veraltete - und selbst wenn ihr Gewicht das Gesamtgewicht der Komponenten übersteigt, sparen Sie eine ansehnliche Menge. Alle Prozessoren Netzwerkadapter und Motherboards müssen gleich sein, damit die Computer gut zusammenarbeiten können. Vergessen Sie natürlich nicht RAM und Festplatte für jeden Knoten sowie mindestens einen Optisches Laufwerk für den Masterknoten.
Installieren Sie die Server im Rack. Beginnen Sie unten, damit das Rack oben nicht überladen wird. Sie werden die Hilfe eines Freundes benötigen – zusammengebaute Server können sehr schwer sein und es ist ziemlich schwierig, sie in die Zellen zu stellen, auf denen sie im Rack stehen.
Installieren Sie einen Ethernet-Switch neben dem Rack. Es lohnt sich, den Switch gleich zu konfigurieren: Stellen Sie die Jumbo-Frame-Größe auf 9000 Byte ein, stellen Sie die statische IP-Adresse ein, die Sie in Schritt 1 gewählt haben, und deaktivieren Sie unnötige Protokolle wie SMTP.
Installieren Sie eine Stromverteilungseinheit (PDU oder Power Distribution Unit). Abhängig von der maximalen Last, die die Knoten in Ihrem Netzwerk ausgeben, benötigen Sie möglicherweise 220 Volt für einen Hochleistungscomputer.
Wenn alles eingestellt ist, fahren Sie mit der Konfiguration fort. Linux ist in der Tat das System der Wahl für Hochleistungscluster (HPC) – es ist nicht nur ideal für wissenschaftliches Rechnen, sondern Sie müssen auch nicht bezahlen, um ein System auf Hunderten oder sogar Tausenden von Knoten zu installieren. Stellen Sie sich vor, wie viel es kosten würde Windows-Installation für alle Knoten!
- Beginnen Sie mit der Installation letzte Version BIOS für das Mainboard und Software vom Hersteller, das für alle Server gleich sein sollte.
- Stellen Sie Ihre bevorzugte ein Linux-Distribution auf allen Knoten und auf dem Hauptknoten - ein Verteilungskit mit einer grafischen Oberfläche. Beliebte Systeme: CentOS, OpenSuse, Scientific Linux, RedHat und SLES.
- Der Autor empfiehlt dringend die Verwendung von Rocks Cluster Distribution. Neben der Installation aller erforderlichen Software und Tools für den Cluster bietet Rocks eine hervorragende Methode zum schnellen „Portieren“ mehrerer Kopien des Systems auf ähnliche Server mithilfe von PXE-Boot und dem „Kick Start“-Verfahren von Red Hat.
Installieren Sie die Message Passing-Schnittstelle, den Ressourcenmanager und andere erforderliche Bibliotheken. Wenn Sie Rocks im vorherigen Schritt nicht installiert haben, müssen Sie die erforderliche Software manuell installieren, um die parallele Rechenlogik einzurichten.
- Zu Beginn benötigen Sie ein portables Bash-System wie Torque Resource Manager, mit dem Sie Aufgaben auf mehrere Maschinen aufteilen und verteilen können.
- Fügen Sie Maui Cluster Scheduler zu Torque hinzu, um die Installation abzuschließen.
- Als nächstes müssen Sie eine Message Passing-Schnittstelle einrichten, die für die einzelnen Prozesse in jedem einzelnen Knoten erforderlich ist, um Daten auszutauschen. OpenMP ist die einfachste Option.
- Vergessen Sie nicht die Multithread-Mathematikbibliotheken und -Compiler, die Ihre Programme für verteiltes Rechnen "zusammenbauen". Habe ich schon gesagt, dass man Rocks einfach installieren soll?
Verbinden Sie Computer mit dem Netzwerk. Der Master-Knoten sendet Aufgaben zur Berechnung an Slave-Knoten, die wiederum das Ergebnis zurücksenden müssen, und auch Nachrichten untereinander senden. Und je früher dies geschieht, desto besser.
- Privat verwenden Ethernet-Netzwerk um alle Knoten zu einem Cluster zu verbinden.
- Der Master-Knoten kann auch als NFS-, PXE-, DHCP-, TFTP- und NTP-Server fungieren, wenn er mit Ethernet verbunden ist.
- Sie müssen dieses Netzwerk vom öffentlichen Netzwerk trennen, um sicherzustellen, dass Pakete nicht von anderen im LAN überlappt werden.
Testen Sie den Cluster. Das Letzte, was Sie tun sollten, bevor Sie Benutzern Zugriff auf Rechenleistung gewähren, sind Leistungstests. Der HPL-Benchmark (High Performance Lynpack) ist eine beliebte Option zum Messen der Rechengeschwindigkeit in einem Cluster. Sie müssen Software aus dem Quellcode mit dem höchsten Optimierungsgrad kompilieren, den Ihr Compiler für die von Ihnen gewählte Architektur zulässt.
- Sie müssen natürlich mit allen kompilieren mögliche Einstellungen Optimierungen, die für die von Ihnen gewählte Plattform verfügbar sind. Wenn Sie beispielsweise eine AMD-CPU verwenden, kompilieren Sie Open64 mit einer Optimierungsstufe von -0.
- Vergleichen Sie Ihre Ergebnisse mit TOP500.org, um Ihren Cluster mit den 500 schnellsten Supercomputern der Welt zu vergleichen!
Ich baute meinen ersten „Cluster“ von Einplatinencomputern fast unmittelbar nachdem der Orange Pi PC-Mikrocomputer an Popularität gewann. Es könnte ein "Cluster" mit großer Ausdehnung genannt werden, weil es formal gesehen gerecht war das lokale Netzwerk von vier Boards, die sich gegenseitig „sahen“ und auf das Internet zugreifen konnten.
Das Gerät nahm am Projekt teil [E-Mail geschützt] und konnte sogar etwas zählen. Aber leider kam niemand, um mich von diesem Planeten abzuholen.
Durch das ständige Herumhantieren mit Kabeln, Anschlüssen und microSD-Karten habe ich jedoch viel gelernt. So habe ich zum Beispiel herausgefunden, dass man der angegebenen Leistung des Netzteils nicht trauen sollte, dass es schön wäre, die Last in Bezug auf den Verbrauch zu verteilen, und dass es auf den Leitungsquerschnitt ankommt.
Und ja, ich musste das Energiemanagementsystem „kollektiv farmen“, da der gleichzeitige Start von fünf Singleboardern einen Startstrom in der Größenordnung von 8-10A (5 * 2) erfordern kann! Das ist viel, besonders für Netzteile, die in den Kellern des Landes hergestellt werden, wo wir so gerne alle möglichen ... interessanten Gadgets bestellen.
Ich werde wahrscheinlich mit ihr anfangen. Die Aufgabe wurde auf relativ einfache Aktionen reduziert - schalten Sie nach einer bestimmten Zeit 4 Kanäle in Reihe ein, über die 5 Volt zugeführt werden. Der einfachste Weg, Ihren Plan umzusetzen, ist mit Arduino (das jeder anständige Geek im Überfluss hat) und hier ist so ein Wunderboard mit Ali mit 4 Relais.
Und weißt du, es hat sogar funktioniert.


Die „Kühlschrank-ähnlichen“ Klicks beim Start sorgten jedoch für einige Ablehnung. Erstens lief beim Klicken ein Rauschen durch das Netzteil und es mussten Kondensatoren installiert werden, und zweitens war die gesamte Struktur ziemlich groß.
Also habe ich eines Tages einfach die Relaisbox durch IRL520-basierte Transistorschalter ersetzt.

Dies löste das Problem mit Interferenzen, aber da der Mosfet „Null“ steuert, musste ich die Messingbeine im Rack verlassen, um nicht versehentlich die Masse der Platinen zu verbinden.
Und jetzt ist die Lösung perfekt repliziert und bereits zwei Cluster arbeiten stabil und ohne Überraschungen. Genau wie geplant.

Aber zurück zur Reproduzierbarkeit. Warum Netzteile für einen beträchtlichen Betrag kaufen, wenn Ihnen viele erschwingliche ATXs buchstäblich unter den Füßen liegen?
Außerdem haben sie alle Spannungen (5,12,3,3), die Ansätze zur Eigendiagnose und die Möglichkeit der Programmsteuerung.
Nun, hier werde ich nicht besonders kreuzigen - ein Artikel über die ATX-Steuerung durch Arduino.
Na, alle Pillen sind gegessen, die Briefmarken sind auch geklebt? Es ist Zeit, alles zusammenzufügen.

Es wird einen Hauptknoten geben, der sich über WiFi mit der Außenwelt verbindet und dem Cluster „Internet“ gibt. Es wird mit ATX-Standby-Spannung betrieben.
Tatsächlich ist TBNG für die Verbreitung des Internets verantwortlich.
Auf Wunsch können also Cluster-Knoten hinter TOR versteckt werden.
Außerdem wird es ein kniffliges Board geben, das über i2c mit diesem Hauptknoten verbunden ist. Sie kann jeden der 10 Worker-Knoten ein- und ausschalten. Außerdem kann er drei 12-V-Lüfter steuern, um das gesamte System zu kühlen.
Das Szenario ist wie folgt: Wenn ATX bei 220 V eingeschaltet wird, startet der Hauptknoten. Wenn das System betriebsbereit ist, schaltet es nacheinander alle 10 Knoten und Lüfter ein.
Wenn der Einschaltvorgang abgeschlossen ist, umgeht der Kopfknoten jeden funktionierenden Knoten und fragt, wie wir uns fühlen, wie hoch die Temperatur sein soll. Wenn eines der Racks beheizt ist, erhöhen Sie den Luftstrom.
Nun, mit dem Shutdown-Befehl wird jeder der Knoten sorgfältig gelöscht und stromlos gemacht.
Ich habe das Board-Diagramm selbst gezeichnet, daher sieht es gruselig aus. Die Nachverfolgung und Herstellung übernahm jedoch eine gut ausgebildete Person, wofür ihm herzlichen Dank gebührt.
Hier wird gerade zusammengebaut.

Hier ist eine der ersten Skizzen der Lage der Cluster-Komponenten. Auf einem Blatt Papier in einem Käfig erstellt und durch Office Lens mit einem Telefon verewigt.

Die gesamte Struktur wird auf eine Textolite-Platte gelegt, die für diesen Anlass gekauft wurde.
So sieht die Anordnung der Knoten im Inneren aus. Zwei Racks mit fünf Brettern.

Hier sieht man die Steuerung Arduino. Es ist über i2c über einen Pegelwandler mit dem Haupt-Orange-Pi-PC verbunden.
Nun, hier ist die endgültige (aktuelle Version).

Alles, was Sie also brauchen, ist, ein paar Python-Dienstprogramme zu schreiben, die all diese Musik leiten würden - schalten Sie es ein, schalten Sie es ein, passen Sie die Lüftergeschwindigkeit an.
Ich will Sie nicht mit den technischen Details langweilen - es sieht in etwa so aus:
| 1
2 3 4 5 6 7 8 | #!/usr/bin/env sh echo "ATX-Board wird gestartet..." /home/zno/i2creobus/i2catx_tool.py --start Echo "Lüfter-Anfangswerte einstellen..." /home/zno/i2creobus/i2creobus_tool.py --fan 0 --set 60 /home/zno/i2creobus/i2creobus_tool.py --fan 1 --set 60 /home/zno/i2creobus/i2creobus_tool.py --fan 2 --set 60 |
Da wir bereits über 10 Nodes verfügen, setzen wir auf Ansible, das beispielsweise hilft, alle Nodes korrekt herunterzufahren. Oder laufen Sie auf jedem Temperaturmonitor.
| 1
2 3 4 5 6 7 8 | ---
- Gastgeber: Arbeiter Rollen: - webmon_stop -webmon_remove - webmon_install - webmon_start |
Mir wird oft ein abschätziger Ton vorgeworfen, dass dies nur ein lokales Netzwerk von Einzelzahlern sei (wie ich ganz am Anfang erwähnt habe). Im Allgemeinen ist mir die Meinung anderer scheißegal, aber vielleicht bringen wir etwas Glamour hinzu und organisieren einen Docker-Schwarm-Cluster.
Die Aufgabe ist sehr einfach und dauert weniger als 10 Minuten. Dann führen wir eine Instanz von Portainer auf dem Hauptknoten aus, und voila!

Jetzt kannst du Ja wirklich Aufgaben skalieren. Im Moment arbeitet also der Kryptowährungs-Miner Verium Reserve im Cluster. Und das ziemlich erfolgreich. Ich hoffe, der nächste Eingeborene zahlt den verbrauchten Strom ab;) Nun, oder reduzieren Sie die Anzahl der beteiligten Knoten und schürfen Sie etwas anderes wie Turtle Coin.

Wenn Sie eine Nutzlast wünschen, können Sie Hadoop in den Cluster werfen oder einen Ausgleich von Webservern arrangieren. Im Internet gibt es viele fertige Bilder, und es gibt genügend Schulungsmaterial. Nun, wenn das Image (Docker-Image) fehlt, können Sie jederzeit ein eigenes erstellen.
Was hat es mich gelehrt? Generell ist der „Stack“ an Technologien sehr breit. Überzeugen Sie sich selbst – Docker, Ansible, Python, Arduino-Upgrade (Gott vergib mir, es wird nicht bei Nacht gesagt) und natürlich die Shell. Sowie KiCad und Arbeit mit einem Auftragnehmer :).
Was kann besser gemacht werden? Viel. Auf der Softwareseite wäre es schön, Kontroll-Utilities in Go umzuschreiben. Auf dem Eisen - machen Sie es steampunkiger - KDPV legt zu Beginn die Messlatte perfekt höher. Es gibt also etwas zu tun.
Gespielte Rollen:
- Die Kopfstelle ist ein Orange Pi PC mit USB-WLAN.
- Arbeitsknoten - Orange Pi PC2 x 10.
- Netzwerk - 100 Mbit/s [E-Mail geschützt]
- Brain - Arduino-Klon basierend auf Atmega8 + Pegelwandler.
- Das Herzstück ist ein ATX-Leistungsregler mit Netzteil.
- Soft (Seele) - Docker, Ansible, Python 3, ein bisschen Shell und ein bisschen Faulheit.
- Die aufgewendete Zeit ist unbezahlbar.
Während der Experimente litten einige Orange Pi PC2-Boards unter einer vertauschten Stromversorgung (sie brennen sehr gut), ein anderer PC2 verlor sein Ethernet (dies ist eine separate Geschichte, in der ich die Physik des Prozesses nicht verstehe).
Das scheint die ganze Geschichte „on top“ zu sein. Wenn es jemand interessant findet - stellen Sie Fragen in den Kommentaren. Und dort für Fragen abstimmen (plus - jeder Kommentar hat dafür einen Button). Die meisten interessante Fragen werden in neuen Notizen behandelt.
Vielen Dank für das Lesen bis zum Ende.
(Übrigens, gleichzeitig ist es möglich, einen kostengünstigen und effizienten Cluster aus einer Xbox 360 oder PS3 zusammenzustellen, die Prozessoren dort sind ungefähr die gleichen wie bei Power, und Sie können mehr als eine Set-Top-Box kaufen eine Million.)
Davon ausgehend zeigen wir preislich interessante Optionen zum Aufbau eines leistungsfähigen Systems auf. Natürlich muss es Multiprozessor sein. Intel verwendet für solche Aufgaben Xeon-Prozessoren, während AMD Opteron-Prozessoren verwendet.
Wenn viel Geld

 Unabhängig davon erwähnen wir eine extrem teure, aber produktive Prozessorreihe, die auf dem Intel Xeon LGA1567-Sockel basiert.
Unabhängig davon erwähnen wir eine extrem teure, aber produktive Prozessorreihe, die auf dem Intel Xeon LGA1567-Sockel basiert. Der Top-Prozessor dieser Serie ist der E7-8870 mit zehn 2,4-GHz-Kernen. Sein Preis beträgt 4616 $. Für solche CPUs geben HP und Supermicro frei! Acht-Prozessor! Servergehäuse. Acht Xeon E7-8870 2,4-GHz-Prozessoren mit 10 Kernen und HyperThreading-Unterstützung unterstützen 8*10*2=160 Threads, die im Windows-Task-Manager als 160-Prozessorlastdiagramme mit einer 10x16-Matrix angezeigt werden.
Damit acht Prozessoren in das Gehäuse passen, werden diese nicht gleich aufgesetzt Hauptplatine, sondern auf separaten Platinen, die in die Hauptplatine gesteckt werden. Das Foto zeigt vier Platinen mit auf der Hauptplatine installierten Prozessoren (jeweils zwei). Dies ist eine Supermicro-Lösung. Bei der HP-Lösung hat jeder Prozessor seine eigene Platine. Die Kosten der HP-Lösung belaufen sich auf zwei bis drei Millionen, je nach Auslastung von Prozessoren, Speicher und anderem. Das Chassis von Supermicro kostet 10.000 US-Dollar, was attraktiver ist. Darüber hinaus kann Supermicro vier Coprozessor-Erweiterungskarten in PCI-Express-x16-Ports stecken (übrigens wird noch Platz für einen Infiniband-Adapter sein, um daraus einen Cluster zusammenzustellen), und HP hat nur zwei. Daher ist die Acht-Prozessor-Plattform von Supermicro attraktiver für die Entwicklung eines Supercomputers. Das folgende Foto aus der Ausstellung zeigt eine Supercomputer-Baugruppe mit vier GPU-Platinen.

Dies ist jedoch sehr teuer.
Was ist billiger
Aber es besteht die Aussicht, einen Supercomputer günstiger zusammenzubauen AMD-Prozessoren Opteron G34, Intel Xeon LGA2011 und LGA 1366.Wählen spezifisches Modell, habe ich eine Tabelle zusammengestellt, in der ich den Preis / (Anzahl der Kerne * Frequenz) für jeden Prozessor berechnet habe. Ich habe Prozessoren unter 2 GHz von der Berechnung ausgeschlossen und für Intel - mit einem Bus unter 6,4 GT / s.
| Modell |
Zahl der Kerne |
Frequenz |
Preis, $ |
Preis/Kern, $ |
Preis/Kern/GHz |
| AMD |
|||||
| 6386 SE |
16 |
2,8 |
1392 |
87 |
31 |
| 6380 |
16 |
2,5 |
1088 |
68 |
27 |
| 6378 |
16 |
2,4 |
867 |
54 |
23 |
| 6376 |
16 |
2,3 |
703 |
44 |
19 |
| 6348 |
12 |
2,8 |
575 |
48 |
17 |
| 6344
|
12 |
2,6 |
415 |
35 |
13 |
| 6328 |
8 |
3,2 |
575 |
72 |
22 |
| 6320 |
8 |
2,8 |
293 |
37 |
13 |
| INTEL |
|||||
| E5-2690 |
8 |
2,9 |
2057 |
257 |
89 |
| E5-2680 |
8 |
2,7 |
1723 |
215 |
80 |
| E5-2670 |
8 |
2,6 |
1552 |
194 |
75 |
| E5-2665 |
8 |
2,4 |
1440 |
180 |
75 |
| E5-2660 |
8 |
2,2 |
1329 |
166 |
76 |
| E5-2650 |
8 |
2 |
1107 |
138 |
69 |
| E5-2687W |
8 |
3,1 |
1885 |
236 |
76 |
| E5-4650L |
8 |
2,6 |
3616 |
452 |
174 |
| E5-4650 |
8 |
2,7 |
3616 |
452 |
167 |
| E5-4640 |
8 |
2,4 |
2725 |
341 |
142 |
| E5-4617 |
6 |
2,9 |
1611 |
269 |
93 |
| E5-4610 |
6 |
2,4 |
1219 |
203 |
85 |
| E5-2640 |
6 |
2,5 |
885 |
148 |
59 |
| E5-2630
|
6 |
2,3 |
612 |
102 |
44 |
| E5-2667 |
6 |
2,9 |
1552 |
259 |
89 |
| X5690 |
6 |
3,46 |
1663 |
277 |
80 |
| X5680 |
6 |
3,33 |
1663 |
277 |
83 |
| X5675 |
6 |
3,06 |
1440 |
240 |
78 |
| X5670 |
6 |
2,93 |
1440 |
240 |
82 |
| X5660 |
6 |
2,8 |
1219 |
203 |
73 |
| X5650 |
6 |
2,66 |
996 |
166 |
62 |
| E5-4607 |
6 |
2,2 |
885 |
148 |
67 |
| X5687 |
4 |
3,6 |
1663 |
416 |
115 |
| X5677 |
4 |
3,46 |
1663 |
416 |
120 |
| X5672 |
4 |
3,2 |
1440 |
360 |
113 |
| X5667 |
4 |
3,06 |
1440 |
360 |
118 |
| E5-2643 |
4 |
3,3 |
885 |
221 |
67 |
Fette Kursivschrift zeigt das Modell mit dem minimalen Verhältnis an, unterstrichen - das meiste leistungsstarke AMD und meiner Meinung nach der nächste Xeon in Bezug auf die Leistung.
Daher ist meine Wahl der Prozessoren für einen Supercomputer Opteron 6386 SE, Opteron 6344, Xeon E5-2687W und Xeon E5-2630.
Motherboards
PICMG
Es ist nicht möglich, mehr als vier Erweiterungskarten mit zwei Steckplätzen auf herkömmliche Motherboards zu stecken. Es gibt eine andere Architektur – die Verwendung von Cross-Boards, wie z. B. der BPG8032 PCI Express Backplane.
Eine solche Platine enthält PCI-Express-Erweiterungskarten und eine Prozessorplatine, ähnlich denen, die in den oben diskutierten Servern auf Supermicro-Basis mit acht Prozessoren installiert sind. Aber nur diese Prozessorplatinen entsprechen den PICMG-Industriestandards. Standards entwickeln sich langsam und solche Boards unterstützen oft nicht am meisten moderne Prozessoren. Höchstens werden solche Prozessorplatinen jetzt für zwei Xeon E5-2448L – Trenton BXT7059 SBC produziert.

Ein solches System würde ohne GPU mindestens 5.000 US-Dollar kosten.
TYAN Ready-Plattformen
Für ungefähr den gleichen Betrag können Sie eine fertige Plattform für die Montage von TYAN FT72B7015-Supercomputern erwerben. In diesem können Sie bis zu acht GPUs und zwei Xeon LGA1366 einbauen."Normale" Server-Motherboards
Für LGA2011
Supermicro X9QR7-TF - Auf diesem Motherboard können 4 Erweiterungskarten und 4 Prozessoren installiert werden.Supermicro X9DRG-QF - dieses Board wurde speziell für den Bau von Hochleistungssystemen entwickelt.
Für Opteron
Supermicro H8QGL-6F - Mit diesem Board können Sie vier Prozessoren und drei Erweiterungskarten installierenStärkung der Plattform mit Erweiterungsplatinen
Dieser Markt wird fast vollständig von NVidia erobert, das neben Gaming-Grafikkarten auch Computerkarten herstellt. AMD hat einen kleineren Marktanteil und Intel ist vor relativ kurzer Zeit in diesen Markt eingetreten.Ein Merkmal solcher Coprozessoren ist das Vorhandensein einer großen Menge an RAM an Bord, schnelle Berechnungen mit doppelter Genauigkeit und Energieeffizienz.
| FP32, TFlops | FP64, TFlops | Preis | Speicher, GB | |
| Nvidia Tesla K20X | 3.95 | 1.31 | 5.5 | 6 |
| AMD FirePro S10000 | 5.91 | 1.48 | 3.6 | 6 |
| Intel Xeon Phi 5110P | 1 | 2.7 | 8 | |
| Nvidia GTX Titan | 4.5 | 1.3 | 1.1 | 6 |
| NVIDIA GTX 680 | 3 | 0.13 | 0.5 | 2 |
| AMD HD 7970 GHz-Edition | 4 | 1 | 0.5 | 3 |
| AMD HD 7990 Devil 13 | 2x3,7 | 2x0,92 | 1.6 | 2x3 |
Die Top-Lösung von Nvidia heißt Tesla K20X auf Basis der Kepler-Architektur. Es sind diese Karten, die im weltweit leistungsstärksten Supercomputer Titan stecken. Allerdings hat Nvidia kürzlich veröffentlicht GeForce-Grafikkarte Titan. Bei älteren Modellen wurde die FP64-Leistung auf 1/24 von FP32 (GTX680) reduziert. Aber in Titanium verspricht der Hersteller eine ziemlich hohe Leistung bei Berechnungen mit doppelter Genauigkeit. Lösungen von AMD sind auch gut, aber sie basieren auf einer anderen Architektur und dies kann es schwierig machen, für CUDA (Nvidia-Technologie) optimierte Berechnungen auszuführen.
Die Lösung von Intel - Xeon Phi 5110P ist interessant, da alle Kerne im Coprozessor auf der x86-Architektur basieren und keine spezielle Codeoptimierung erforderlich ist, um die Berechnungen zu starten. Aber mein Lieblings-Coprozessor ist die relativ günstige AMD HD 7970 GHz Edition. Theoretisch wird diese Grafikkarte die maximale Leistung pro Preis zeigen.
Kann geclustert werden
Um die Systemleistung zu verbessern, können mehrere Computer zu einem Cluster zusammengefasst werden, wodurch die Rechenlast auf die Computer verteilt wird, die Teil des Clusters sind.Benutzen als Netzwerkschnittstelle um rechner anzubinden, ist herkömmliches gigabit-ethernet zu langsam. Für diese Zwecke wird am häufigsten Infiniband verwendet. Der Infiniband-Hostadapter ist im Vergleich zum Server kostengünstig. Beispielsweise werden solche Adapter bei der internationalen Ebay-Auktion zu einem Preis von 40 $ verkauft. Beispielsweise kostet die Lieferung eines X4-DDR-Adapters (20 Gb/s) nach Russland etwa 100 US-Dollar.
Gleichzeitig ist die Schaltausrüstung für Infiniband ziemlich teuer. Ja, und wie oben erwähnt, der klassische Stern als Topologie Computernetzwerk- nicht die beste Wahl.
InfiniBand-Hosts können jedoch ohne Switch direkt miteinander verbunden werden. Dann wird zum Beispiel diese Option sehr interessant: ein Cluster aus zwei Computern, die über Infiniband verbunden sind. Ein solcher Supercomputer kann zu Hause zusammengebaut werden.
Wie viele Grafikkarten benötigen Sie
Im leistungsstärksten Supercomputer unserer Zeit, Cray Titan, beträgt das Verhältnis von Prozessoren zu "Grafikkarten" 1: 1, dh er hat 18688 16-Kern-Prozessoren und 18688 Tesla K20X.Bei Tianhe-1A, einem chinesischen Supercomputer auf Basis von Xeons, ist das Verhältnis wie folgt. Zwei Sechs-Kern-Prozessoren für eine Nvidia M2050-Grafikkarte (schwächer als K20X).
Wir werden eine solche Einstellung für unsere Baugruppen als optimal (weil billiger) annehmen. Das heißt, 12-16 Prozessorkerne pro GPU. In der folgenden Tabelle sind praktisch mögliche Optionen fett markiert, die aus meiner Sicht erfolgreichsten unterstrichen.
| Grafikkarte | Kerne | 6-Kern-CPU | 8-Kern-CPU | 12-Kern-CPU | 16-Kern-CPU | |||||
| 2 | 24 | 32 | 4
|
5 |
3
|
4
|
2
|
3
|
2
|
2
|
| 3 | 36 | 48 | 6 |
8 |
5 |
6 |
3
|
4
|
2
|
3
|
| 4 | 48 | 64 | 8 |
11 |
6 |
8 |
4
|
5 |
3
|
4
|
Wenn das System bereits ist etablierte Haltung Prozessoren / Grafikkarten können noch mehr "an Bord" nehmen Rechengeräte, dann werden wir sie hinzufügen, um die Leistung der Versammlung zu erhöhen.
Also wie viel kostet es
Die folgenden Optionen sind ein Supercomputer-Gehäuse ohne RAM, Festplatte und Software. Alle Modelle verwenden den AMD HD 7970 GHz Edition Videoadapter. Es kann auf Anforderung der Task durch ein anderes ersetzt werden (z. B. xeon phi). Wo es das System zulässt, wurde eine der AMD HD 7970 GHz Editionen durch eine AMD HD 7990 Devil 13 mit drei Steckplätzen ersetzt.Option 1 auf dem Supermicro H8QGL-6F Motherboard

| Hauptplatine | Supermikro H8QGL-6F | 1 | 1200 | 1200 |
| Zentralprozessor | AMD Opteron 6344 | 4 | 500 | 2000 |
| CPU-Kühler | Thermaltake CLS0017 | 4 | 40 | 160 |
| Fahrgestell 1400W | SC748TQ-R1400B | 1 | 1000 | 1000 |
| Grafikbeschleuniger | AMD HD 7970 GHz-Edition | 3 | 500 | 1500 |
| 5860 |
Theoretisch wird die Performance bei etwa 12 Tflops liegen.
Option 2 auf TYAN S8232 Motherboard, Cluster

Dieses Board unterstützt Opteron 63xx nicht, daher wird 62xx verwendet. Bei dieser Option werden zwei Computer über Infiniband x4 DDR mit zwei Kabeln geclustert. Theoretisch beruht die Verbindungsgeschwindigkeit in diesem Fall auf der Geschwindigkeit von PCIe x8, dh 32 Gbit / s. Es werden zwei Netzteile verwendet. Wie man sie aufeinander abstimmt, findet man im Internet.
| Menge | Preis | Summe | ||
| Hauptplatine | TYAN S8232 | 1 | 790 | 790 |
| Zentralprozessor | AMD Opteron 6282SE | 2 | 1000 | 2000 |
| CPU-Kühler | Noctua NH-U12DO A3 | 2 | 60 | 120 |
| Rahmen | Antec Zwölfhundert Schwarz | 1 | 200 | 200 |
| Netzteil | FSP AURUMPRO 1200W | 2 | 200 | 400 |
| Grafikbeschleuniger | AMD HD 7970 GHz-Edition | 2 | 500 | 1000 |
| Grafikbeschleuniger | AX79906GBD5-A2DHJ | 1 | 1000 | 1000 |
| Infiniband-Adapter | X4 DDR Infiniband | 1 | 140 | 140 |
| Infiniband-Kabel | X4 DDR Infiniband | 1 | 30 | 30 |
| 5680 (für einen Block) |
Für einen Cluster solcher Konfigurationen werden zwei benötigt und ihre Kosten werden geringer sein $11360 . Seine Leistungsaufnahme bei Volllast beträgt etwa 3000 W. Theoretisch soll die Performance bei bis zu 31Tflops liegen.
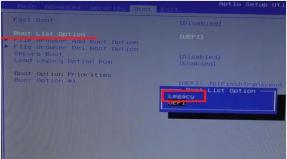
Dieser Artikel zeigt Ihnen, wie Sie einen Server 2012-Failovercluster mit zwei Knoten erstellen. Ich werde zunächst die Voraussetzungen auflisten und einen Überblick über die Hardware-, Netzwerk- und Speichereinstellungen geben. Anschließend wird detailliert beschrieben, wie Sie Server 2012 mit Failover-Clustering-Funktionen erweitern und den Failover-Cluster-Manager verwenden, um einen Zwei-Knoten-Cluster einzurichten.
Es gibt so viele neue Funktionen in Windows Server 2012, dass es schwierig ist, den Überblick zu behalten. Einige der wichtigsten Bausteine einer neuen IT-Infrastruktur beziehen sich auf Verbesserungen beim Failover-Clustering. Failover-Clustering entstand als Technologie zum Schutz kritischer Anwendungen, die für Geschäftsvorgänge wie Microsoft erforderlich sind SQL Server und Microsoft Exchange. In der Folge hat sich das Failover-Clustering jedoch zu einer Hochverfügbarkeitsplattform für eine Reihe von Diensten und Diensten entwickelt Windows-Anwendungen. Failover-Clustering ist Teil der Grundlage von Dynamic Datacenter und Technologien wie Live-Migration. Mit Server 2012 und neuen Verbesserungen Protokollserver Message Block (SMB) 3.0 begann der Umfang des Failover-Clusterings zu steigen und sorgte für kontinuierlich verfügbare Dateifreigaben öffentlicher Zugang. Eine Übersicht über die Failover-Clustering-Funktionalität in Server 2012 finden Sie unter What's New in Windows Server 2012 Failover Clustering, veröffentlicht in derselben Ausgabe.
Voraussetzungen für das Failover-Clustering
Zum Erstellen eines Server 2012-Failoverclusters mit zwei Knoten sind zwei Computer erforderlich, auf denen Server 2012 Datacenter oder Standard Editionen ausgeführt werden. Dies können physische Computer oder virtuelle Maschinen sein. Virtuelle Knotencluster können mit erstellt werden Hilfe von Microsoft Hyper-V oder VMware vSphere. Dieser Artikel verwendet zwei physische Server, aber die Clusterkonfigurationsschritte für physische und virtuelle Knoten sind identisch. Hauptmerkmale besteht darin, dass die Knoten gleich konfiguriert sein müssen, damit der Standby-Knoten Arbeitslasten im Falle eines Failover oder einer Live-Migration ausführen kann. Die im Server 2012-Testfailovercluster verwendeten Komponenten sind in der Abbildung dargestellt.
Ein Server 2012-Failovercluster erfordert gemeinsam genutzten Speicher vom Typ iSCSI, Serially Attached SCSI oder Fibre Channel SAN. In unserem Beispiel wird iSCSI SAN verwendet. Beachten Sie die folgenden Merkmale von Speichern dieses Typs.
- Jeder Server muss über mindestens drei Netzwerkadapter verfügen: einen für den Anschluss des iSCSI-Speichers, einen für die Kommunikation mit dem Cluster-Knoten und einen für die Kommunikation mit dem externen Netzwerk. Wenn Sie planen, einen Cluster für die Live-Migration zu verwenden, ist es sinnvoll, einen vierten Netzwerkadapter zu haben. Die Live-Migration kann jedoch auch über eine externe durchgeführt werden Netzwerkverbindung- es wird nur langsamer laufen. Wenn Server für die Hyper-V-basierte Virtualisierung und Serverkonsolidierung verwendet werden, sind zusätzliche Netzwerkadapter erforderlich, um den Netzwerkdatenverkehr weiterzuleiten virtuelle Maschinen.
- Schnellere Netzwerke funktionieren immer am besten, daher sollte die iSCSI-Verbindungsgeschwindigkeit mindestens 1 GHz betragen.
- Der Zweck von iSCSI muss mit der iSCSI-3-Spezifikation übereinstimmen, insbesondere um dauerhafte Redundanz bereitzustellen. Dies ist eine zwingende Voraussetzung für die Live-Migration. Die Hardware fast aller Speicheranbieter ist kompatibel mit iSCSI 3. Wenn Sie einen Cluster in einer Laborumgebung kostengünstig einrichten müssen, stellen Sie sicher, dass Ihre iSCSI-Zielsoftware mit iSCSI 3 kompatibel und immer redundant ist. Ältere Versionen von Openfiler unterstützen diesen Standard im Gegensatz zu neue Version Openfiler mit Advanced iSCSI Target Plugin (http://www.openfiler.com/products/advanced-iscsi-plugin). Außerdem, Freie Version StarWind iSCSI SAN Free Edition von StarWind Software (http://www.starwindsoftware.com/starwind-free) ist vollständig kompatibel mit Hyper-V und Live-Migration. Etwas Microsoft-Versionen Windows Server kann auch als iSCSI-Ziel fungieren, das mit den Standards iSCSI 3 kompatibel ist Server 2012 enthält ein iSCSI-Ziel. Windows Storage Server 2008 R2 unterstützt iSCSI-Zielsoftware. Darüber hinaus können Sie herunterladen Microsoft-Programm iSCSI Software Target 3.3 (http://www.microsoft.com/en-us/download/details.aspx?id=19867), das mit Windows Server 2008 R2 funktioniert.
Weitere Informationen zum Konfigurieren von iSCSI-Speicher für einen Failover-Cluster finden Sie in der Seitenleiste „iSCSI-Speicherkonfigurationsbeispiel“. Weitere Informationen zu den Anforderungen für das Failover-Clustering finden Sie unter Hardwareanforderungen und Speicheroptionen für das Failover-Clustering (http://technet.microsoft.com/en-us/library/jj612869.aspx).
Hinzufügen von Failover-Clustering-Funktionen
Der erste Schritt zum Erstellen eines Server 2012-Failoverclusters mit zwei Knoten besteht darin, das Failoverclusterfeature mithilfe des Server-Managers hinzuzufügen. Der Server-Manager wird automatisch geöffnet, wenn Sie sich bei Server 2012 anmelden. Um eine Failover-Cluster-Funktion hinzuzufügen, wählen Sie Lokaler Server aus und scrollen Sie nach unten zum Abschnitt ROLLEN UND FUNKTIONEN. Wählen Sie in der Dropdown-Liste AUFGABEN die Option Rollen und Features hinzufügen aus, wie in Abbildung 1 dargestellt. Dadurch wird der Assistent zum Hinzufügen von Rollen und Features gestartet.
Die erste Seite, die beim Ausführen des Assistenten geöffnet wird, ist die Begrüßungsseite Bevor Sie beginnen. Klicken Sie auf die Schaltfläche Weiter, um zur Auswahlseite für den Installationstyp zu gelangen, auf der Sie gefragt werden, ob Sie die Komponente auf einem lokalen Computer oder in einem Dienst installieren möchten Remotedesktop. Wählen Sie für dieses Beispiel die Option Rollenbasierte oder funktionsbasierte Installation und klicken Sie auf Weiter.
Wählen Sie auf der Seite Zielserver auswählen den Server aus, auf dem Sie die Failover-Clustering-Features installieren möchten. In meinem Fall ist es lokaler Server namens WS2012-N1. Klicken Sie bei ausgewähltem lokalen Server auf Weiter, um mit der Seite Serverrollen auswählen fortzufahren. In diesem Beispiel ist die Serverrolle nicht installiert, also klicken Sie auf Weiter. Oder Sie können im linken Menü auf den Link Funktionen klicken.
Scrollen Sie auf der Seite Features auswählen in der Liste der Features nach unten zu Failoverclustering. Klicken Sie in das Feld vor Failover-Clustering und Sie sehen ein Dialogfeld, in dem die verschiedenen Komponenten aufgeführt sind, die als Teil dieser Komponente installiert werden. Wie Abbildung 2 zeigt, installiert der Assistent standardmäßig die Failovercluster-Verwaltungstools und das Failovercluster-Modul für Windows PowerShell. Klicken Sie auf die Schaltfläche „Features hinzufügen“, um zur Seite „Feature Selection“ zurückzukehren. Weiter klicken.
Auf der Seite Installationsauswahl bestätigen wird die Failover-Clustering-Funktion zusammen mit den Verwaltungstools und dem PowerShell-Modul angezeigt. Von dieser Seite aus können Sie zurückkehren und Änderungen vornehmen. Wenn Sie auf die Schaltfläche Installieren klicken, beginnt die eigentliche Installation der Komponenten. Sobald die Installation abgeschlossen ist, wird der Assistent abgeschlossen und die Failover-Clustering-Funktion wird unter ROLLEN UND FUNKTIONEN im Server-Manager angezeigt. Dieser Vorgang muss auf beiden Knoten abgeschlossen werden.
Failover-Cluster-Tests
Der nächste Schritt nach dem Hinzufügen der Failover-Clustering-Funktion besteht darin, die Einstellungen der Umgebung zu überprüfen, in der der Cluster erstellt wurde. Hier können Sie den Assistenten zum Überprüfen der Einstellungen im Failovercluster-Manager verwenden. Dieser Assistent überprüft die Hardwareparameter und Software aller Knoten im Cluster und meldet alle Probleme, die die Organisation des Clusters beeinträchtigen könnten.
Um den Failovercluster-Manager zu öffnen, wählen Sie die Option Failovercluster-Manager im Menü Extras im Server-Manager aus. Klicken Sie im Verwaltungsbereich auf den Link Validate Configuration (siehe Abbildung 3), um den Validate Configuration Wizard zu starten.
.jpg) |
| Abbildung 3: Ausführen des Configuration Check Wizard |
Zuerst wird die Begrüßungsseite des Assistenten angezeigt. Klicken Sie auf die Schaltfläche Weiter, um mit der Seite Serverauswahl oder Cluster fortzufahren. Geben Sie auf dieser Seite die Knotennamen des Clusters ein, den Sie testen möchten. Ich habe WS2012-N1 und WS2012-N2 angegeben. Klicken Sie auf die Schaltfläche Weiter, um die Seite Testoptionen anzuzeigen, auf der Sie bestimmte Testsuiten auswählen oder alle Tests ausführen können. Zumindest beim ersten Mal empfehle ich, alle Tests durchzuführen. Klicken Sie auf die Schaltfläche Weiter, um zur Bestätigungsseite zu gelangen, auf der die laufenden Tests angezeigt werden. Klicken Sie auf die Schaltfläche Weiter, um den Cluster-Testprozess zu starten. Beim Testen wird die Version überprüft Betriebssystem, Netzwerk- und Speichereinstellungen aller Clusterknoten. Nach Abschluss des Tests wird eine Zusammenfassung der Ergebnisse angezeigt.
Wenn die Validierungstests erfolgreich sind, können Sie einen Cluster erstellen. Abbildung 4 zeigt den Zusammenfassungsbildschirm für einen erfolgreich validierten Cluster. Werden bei der Prüfung Fehler gefunden, wird der Bericht markiert gelbes Dreieck(Warnungen) oder ein rotes „X“ für schwerwiegende Fehler. Warnungen sollten gelesen werden, können aber ignoriert werden. Schwerwiegende Fehler müssen behoben werden, bevor der Cluster erstellt werden kann.
Als Ergebnis wird der Cluster-Erstellungs-Assistent gestartet, beginnend mit der Willkommensseite. Klicken Sie auf Weiter, um zur in Abbildung 6 gezeigten Serverauswahlseite zu wechseln. Geben Sie auf dieser Seite die Namen aller Knoten im Cluster ein und klicken Sie dann auf Weiter.
Auf der Seite Zugriffspunkt für die Verwaltung des Clusters müssen Sie den Namen und die IP-Adresse des Clusters angeben, die im Netzwerk eindeutig sein müssen. Abbildung 7 zeigt, dass mein Clustername WS2012-CL01 und die IP-Adresse 192.168.100.200 lautet. Bei Verwendung von Server 2012 kann die Cluster-IP-Adresse per DHCP zugewiesen werden, aber ich bevorzuge eine statisch zugewiesene IP-Adresse für meine Server.
Klicken Sie nach Eingabe des Namens und der IP-Adresse auf die Schaltfläche Weiter, um die Bestätigungsseite anzuzeigen (Bildschirm 8). Auf dieser Seite können Sie die Einstellungen überprüfen, die Sie beim Erstellen des Clusters vorgenommen haben. Sie können zurückgehen und bei Bedarf Änderungen vornehmen.
Nachdem Sie auf der Bestätigungsseite auf die Schaltfläche Weiter geklickt haben, wird auf allen ausgewählten Knoten ein Cluster gebildet. Die Fortschrittsseite zeigt die Schritte des Assistenten beim Erstellen eines neuen Clusters. Nach Abschluss zeigt der Assistent eine Zusammenfassungsseite mit den Einstellungen für den neuen Cluster an.
Der Assistent für neue Cluster wählt automatisch den Speicher für das Quorum aus, aber häufig wählt er nicht die Quorum-Festplatte aus, die der Administrator möchte. Um zu überprüfen, welcher Datenträger für das Quorum verwendet wird, öffnen Sie den Failovercluster-Manager und erweitern Sie den Cluster. Öffnen Sie dann den Knoten Storage und klicken Sie auf den Knoten Disks. Die im Cluster verfügbaren Festplatten werden im Bereich „Festplatten“ angezeigt. Die vom Assistenten für das Cluster-Quorum ausgewählte Festplatte wird unter Disk Witness in Quorum aufgeführt.
In diesem Beispiel wurde für das Quorum Cluster Disk 4 verwendet, dessen Größe mit 520 MB etwas größer ist als der Mindestwert für ein Quorum von 512 MB. Wenn Sie einen anderen Datenträger für das Cluster-Quorum verwenden möchten, können Sie die Cluster-Einstellungen ändern, indem Sie im Failovercluster-Manager mit der rechten Maustaste auf den Cluster-Namen klicken, Weitere Aktionen auswählen und Cluster-Quorum-Einstellungen konfigurieren auswählen. Dadurch wird der Assistent zum Auswählen des Quorums angezeigt, mit dem Sie die Cluster-Quorum-Einstellungen ändern können.
Konfigurieren von Cluster Shared Volumes und Virtual Machine-Rollen
Beide Knoten in meinem Cluster haben die Hyper-V-Rolle, da der Cluster für hochverfügbare virtuelle Maschinen für die Live-Migration ausgelegt ist. Um die Live-Migration zu vereinfachen, besteht der nächste Schritt darin, Cluster Shared Volumes (CSV) zu konfigurieren. Im Gegensatz zu Server 2008 R2 sind freigegebene Clustervolumes in Server 2012 standardmäßig aktiviert. Sie müssen jedoch noch angeben, welcher Speicher für Cluster Shared Volumes verwendet werden soll. Um CSV auf einem verfügbaren Datenträger zu aktivieren, erweitern Sie den Speicherknoten und wählen Sie den Knoten Datenträger aus. Wählen Sie dann den Clusterdatenträger aus, den Sie als CSV-Datei verwenden möchten, und klicken Sie im Bereich „Aktionen“ des Failovercluster-Managers auf den Link „Zu freigegebenen Clustervolumes hinzufügen“ (Abbildung 9). Das Feld „Assigned To“ dieses Clusterdatenträgers ändert sich von „Available Storage“ zu „Cluster Shared Volume“, wie in Abbildung 9 gezeigt.
Zu diesem Zeitpunkt konfiguriert der Failovercluster-Manager den Cluster-Datenträgerspeicher für CSV, indem er insbesondere einen Bereitstellungspunkt hinzufügt Systemlaufwerk. In diesem Beispiel werden freigegebene Clustervolumes sowohl auf Cluster-Datenträger 1 als auch auf Cluster-Datenträger 3 aktiviert, indem die folgenden Bereitstellungspunkte hinzugefügt werden:
* C:ClusterStorageVolume1 *C:ClusterStorageVolume2
Zu diesem Zeitpunkt wurde ein Server 2012-Cluster mit zwei Knoten erstellt und freigegebene Clustervolumes aktiviert. Anschließend können Sie geclusterte Anwendungen installieren oder dem Cluster Rollen hinzufügen. In diesem Fall wurde der Cluster für die Virtualisierung erstellt, also fügen wir dem Cluster die Rolle der virtuellen Maschine hinzu.
Um eine neue Rolle hinzuzufügen, wählen Sie den Clusternamen im Navigationsbereich des Failovercluster-Managers aus und klicken Sie im Bereich Aktionen auf den Link Rollen konfigurieren, um den Assistenten für hohe Verfügbarkeit zu starten. Klicken Sie auf der Willkommensseite auf die Schaltfläche Weiter, um zur Rollenauswahlseite zu gelangen. Scrollen Sie durch die Liste der Rollen, bis Sie die Rolle der virtuellen Maschine sehen, wie in Abbildung 10. Wählen Sie die Rolle aus und klicken Sie auf Weiter.
Auf der VM-Auswahlseite werden alle VMs auf allen Cluster-Knoten aufgelistet, wie in Abbildung 11 gezeigt. Scrollen Sie durch die Liste und wählen Sie die VMs aus, die hochverfügbar sein sollen. Klicken Sie auf die Schaltfläche Weiter. Nachdem Sie Ihre Auswahl bestätigt haben, klicken Sie auf Weiter, um die Rollen der virtuellen Maschine zum Failovercluster-Manager hinzuzufügen.
Beispiel für eine iSCSI-Speicherkonfiguration
Für Ausfallsicherheit Windows-Cluster Server 2012 erfordert gemeinsam genutzten Speicher, der iSCSI, Serially Attached SCSI oder Fibre Channel SAN sein kann. Dieser Failovercluster verwendet ein Kanal-SAN.
Zuerst wurden drei LUNs auf dem iSCSI-SAN erstellt. Eine LUN wurde für den Quorum-Datenträger des Clusters (520 MB) erstellt. Die andere LUN ist für 10 VMs und hat eine Größe von 375 GB. Die dritte LUN ist einer kleinen Test-VM gewidmet. Alle drei LUNs sind im NTFS-Format.
Nachdem die LUNs erstellt wurden, wurde der iSCSI-Initiator auf beiden Knoten von Server 2012 konfiguriert.Um iSCSI-Ziele hinzuzufügen, wurde der iSCSI-Initiator aus dem Menü „Extras“ im Server-Manager ausgewählt. Auf der Registerkarte Discovery habe ich auf die Schaltfläche Discover Portal geklickt. Als Ergebnis erschien das Dialogfeld Discover Portal, in dem die IP-Adresse (192.168.0.1) und der iSCSI-Port (3260) des SAN eingegeben wurden.
Dann ging ich zur Registerkarte Ziele und klickte auf die Schaltfläche Verbinden. Im Dialogfeld „Mit Ziel verbinden“ habe ich den Namen des iSCSI-SAN-Ziels eingegeben. Es wurde aus den Eigenschaften des SAN erhalten. Der Name hängt vom SAN-Anbieter, dem Domänennamen und den Namen der erstellten LUNs ab. Zusätzlich zum Zielnamen habe ich den Modus so eingestellt, dass er diese Verbindung zur Liste der bevorzugten Ziele hinzufügt.
Nachdem die iSCSI-Einrichtung abgeschlossen war, wurden diese LUNs auf der Registerkarte „Ziele“ des iSCSI-Initiators angezeigt. Um LUNs beim Start von Server 2012 automatisch bereitzustellen, habe ich dafür gesorgt, dass sie auf der Registerkarte „Favorite Targets“ aufgelistet sind, wie Abbildung A zeigt.
.jpg) |
| Bildschirm A. iSCSI-Initiator konfigurieren |
Abschließend wurden den LUNs mit dem Disk-Snap-In Buchstaben zugewiesen Managementkonsole Microsoft-Verwaltung (MMC). Ich habe Q für den Quorum-Datenträger und W für den Datenträger gewählt, der für virtuelle Maschinen und freigegebene Cluster-Volumes (CSV) verwendet wird. Wenn Sie Laufwerksbuchstaben zuweisen, müssen Sie diese zuerst auf demselben Knoten zuweisen. Dann müssen Sie die Festplatten offline schalten und ähnliche Zuweisungen auf dem zweiten Knoten vornehmen. Die Ergebnisse der Laufwerksbuchstabenzuweisung für einen einzelnen Knoten sind in Abbildung B dargestellt. Wenn Sie einen Cluster erstellen, werden die Laufwerke als verfügbarer Speicher angezeigt.