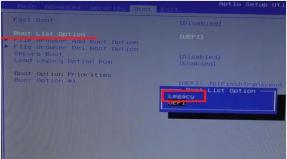
Partisi server sql. Membuat model database fisik: rekayasa kinerja. Penyaringan Bagian Statis
PADA kondisi modern sangat aneh kadang-kadang mendengar "kita perlu menutup database 1C - volumenya melebihi 50 GB". Jika administrator sistem SAP R3 atau Oracle e Business Suite atau bahkan MS Dynamics Axe akan melakukan ini, mereka mungkin akan dipecat. Namun, untuk 1C ini adalah "praktik standar".
Untuk versi file, cerita kembali ke versi 1C 7.7 dengan batas 2GB pada ukuran database. Sekarang batas 2GB hanya pada ukuran tabel, ukuran file sudah bisa menjadi sangat-sangat kecil. Benar, jika basis data Anda telah berkembang menjadi ukuran seperti itu, maka mungkin data dimasukkan secara aktif di sana - mungkin Anda perlu memikirkan server-klien?
Sebenarnya, tujuan artikel ini adalah untuk "menghalangi" pengguna 1C versi client-server dari melakukan rollup basis data, melalui penggunaan teknologi yang agak lebih "maju".
Angka terakhir adalah 30-40 ton setidaknya terhadap 20-25 dalam hal pembelian perangkat keras, dan dapatkan ruang tambahan sebesar 500 GB
Jadi ada produk seperti
Mungkin produk yang bagus, dan mereka memenuhi tujuan mereka. Hanya saja struktur tabelnya berubah dari versi ke versi platform. 1C kami telah diberitahu tentang hal ini lebih dari sekali. Ada pemisah data di rilis ke-14 dan hanya itu ... kemungkinan besar pemrosesan untuk rilis ke-14 ini tidak lagi cocok. Ya, dan entah bagaimana menakutkan, belum lagi pelanggaran perjanjian lisensi.
Dan bahkan setelah itu, akan ada pengguna yang "tiba-tiba membutuhkan" data yang terhapus, yang "hanya ingin mengoreksi" beberapa nomor yang "tidak mempengaruhi urutan" dalam dokumen periode tertutup. Dan lebih buruk lagi jika ternyata seseorang terus-menerus melihat dokumen-dokumen ini untuk beberapa tujuan yang hanya diketahui olehnya. Tentu saja, ini semua hanya kesalahan dalam metode kerja, tetapi bagaimanapun, pengguna akan tidak puas.
-
Buka Management Studio di daftar database, pilih yang Anda butuhkan, buka propertinya.
- Buka tab "Filegroups" seperti yang ditunjukkan pada gambar, dan tambahkan filegroup lain (dalam contoh ini disebut SECONDARY)
- Buka tab "File" dan tambahkan file baru, di mana kami memilih filegroup yang dibuat. File ini DAPAT DITEMUKAN DI DISK LAIN
-
Sekarang, menggunakan pemrosesan, misalnya: kami menentukan tabel mana yang dapat kami "sumbangkan" dengan aman ke media yang lebih lambat (baik, atau sebaliknya, semuanya ke media yang lambat, sisanya ke media yang lebih cepat). Aturan 80/20 berlaku di sini. 80% operasi dilakukan dengan 20% data, jadi pikirkan pelat mana yang Anda butuhkan dengan cepat dan mana yang tidak terlalu banyak. "Penyimpanan informasi tambahan", dokumen untuk memasukkan saldo awal, dokumen yang tidak lagi Anda gunakan segera didefinisikan sebagai dokumen yang dapat ditransfer ke grup file "lambat".
Pilih tabel yang perlu dipindahkan ke grup file lain - pilih menu untuk mengubah tabel (proyek) dan ubah grup file di properti:
indeks tabel juga ditransfer ke filegroup ini.
Mekanisme yang cukup nyaman untuk mendistribusikan tabel di seluruh array disk kecepatan yang berbeda. Ini tidak bertentangan dengan perjanjian lisensi, karena. dalam penyelesaiannya, kami tidak menggunakan akses data dan basis informasi dengan cara selain platform 1C. Kami hanya mengatur penyimpanan data ini dengan cara yang nyaman.
DBCC TRACEON (1807)
Kami menulis perintah ini di Management Studio, kami menjalankannya dan kami berhasil membuat database melalui jaringan. Tentu saja, dalam hal ini, sebuah contoh SQL Server harus dijalankan atas nama domain Akun, dan entri ini harus memiliki hak atas yang diinginkan folder jaringan.
Tapi harap berhati-hati saat menggunakan perintah ini jika Anda kehilangan jaringan saat bekerja dengan database, seluruh database tidak akan tersedia selama tidak ada. Microsoft dengan sengaja menutup kesempatan ini untuk penggunaan massal. Secara umum, fitur ini seharusnya membuat database pada penyimpanan NAS, yang sangat saya rekomendasikan. Cocok sebagai stabil dan dapat diandalkan server file memiliki koneksi langsung ke server yang menjalankan MS SQL DBMS.
Anda dapat membaca selengkapnya tentang bendera jejak lainnya di artikel http://msdn.microsoft.com/en-us/library/ms188396.aspx
Itu. bagian dari filegroup umumnya dapat disimpan di jaringan, dan bahkan di sana ruang disk mengembang tanpa masalah.
Membagi tabel ke dalam grup file yang berbeda tentu saja baik-baik saja... tetapi Anda akan mengatakan bahwa ada beberapa tabel di sini... yang telah berlangsung sejak tahun 2005... dan sudah menempati selusin gigabyte.. Saya berharap mereka punya semua data, ya disk terpisah menempatkan, dan meninggalkan saat ini.
Anda tidak akan percaya, tetapi ini juga mungkin, meskipun tidak terlalu sederhana:
Buat fungsi partisi berdasarkan tanggal:
buat fungsi partisi YearSection(datetime)
sebagai rentang yang tepat untuk nilai ("20110101");
Semuanya sebelum 2011 akan jatuh ke dalam satu bagian, semuanya setelah - ke bagian lain.
Buat skema partisi
buat skema partisi YearScheme
sebagai partisi YearSection ke (SECONDARY, PRIMARY);
Dengan ini kami mengatakan bahwa semua data hingga tahun 11 akan masuk ke grup file "Sekunder" dan setelah - ke "Utama"
Sekarang tinggal membangun kembali tabel dengan pembagian menjadi beberapa bagian. Untuk ini, cara termudah adalah menggunakan studio manajemen, karena prosesnya tidak sederhana. Anda perlu membangun kembali indeks berkerumun di atas tabel (yang pada dasarnya adalah tabel itu sendiri) menggunakan skema partisi yang Anda buat untuk indeks:
Dalam gambar Anda melihat bahwa pilihan tidak tersedia - semuanya benar, partisi tabel hanya dimungkinkan di MS SQL Server edisi Enterprise. Indeks cluster mudah dibedakan - gambar dengan tanda kurung. Untuk kendaraan peluncuran dan semua objek 1C, itu dibuat. Untuk PH, selalu ada indeks berkerumun berdasarkan periode. Untuk dokumen dan direktori, akan lebih baik untuk membuat yang lain, tentu saja, yang mencakup perincian bagian mana yang akan ... tetapi ini sudah merupakan pelanggaran terhadap perjanjian lisensi.
Tetapi untuk ini Anda tidak perlu meruntuhkan alasnya, tetapi lakukan hal berikut:
a) Jelaskan kepada semua orang bagaimana menggunakan pilihan, bagaimana mereka disimpan, bagaimana menggunakan interval log, bagaimana mereka disimpan
b) Tandai untuk menghapus data yang tidak perlu jika tidak membawa beban semantik (kontraktor dan nomenklatur yang tidak banyak digunakan oleh Anda) - ini akan membawa lebih banyak manfaat bagi pengguna daripada konvolusi. Jika ada sumber daya, atur penandaan otomatis untuk menghapus objek yang tidak digunakan dan buat pilihan secara default di kode program agar tidak menampilkan objek default yang tidak diperlukan pengguna - ditandai untuk dihapus
c) Siapkan "pilihan default" lain yang berguna - misalnya, sehingga setiap manajer hanya melihat dokumennya sendiri secara default. Dan jika dia ingin melihat dokumen "kawan" - Anda harus mematikan seleksi.
Untuk semua detail yang terlibat dalam pemilihan, jangan lupa untuk mengatur bendera "Indeks dengan pemesanan tambahan" - maka "kenyamanan" seperti itu tidak akan memengaruhi kinerja sistem.
Oracle DBMS memiliki kemampuan tampilan partisi. Ide utamanya sederhana. Biarkan tabel fisik dipecah menjadi beberapa tabel (opsional menggunakan metode pembagian tabel) sesuai dengan kriteria partisi yang membuat pemrosesan kueri lebih efisien. Kriteria partisi akan disebut predikat pembagian. Anda kemudian dapat membuat dan menyesuaikan tampilan sedemikian rupa sehingga membuat akses data dalam tabel ini lebih mudah bagi pengguna. Bagian tampilan ditentukan sesuai dengan rentang nilai kunci partisi. Kueri yang menggunakan rentang nilai untuk mengambil data dari bagian tampilan hanya akan mengakses bagian yang cocok dengan rentang nilai kunci partisi.
Lihat bagian dapat ditentukan oleh predikat pembagian ditentukan baik dengan batasan CHECK atau dengan klausa WHERE. Mari tunjukkan bagaimana kedua teknik dapat diterapkan dengan menggunakan contoh tabel Penjualan yang sedikit dimodifikasi, yang telah kita bahas di bagian sebelumnya. Katakanlah data penjualan untuk satu tahun kalender ditempatkan dalam empat tabel terpisah, masing-masing sesuai dengan seperempat tahun - Q1_Sales, Q2_Sales, Q3_Sales, dan Q4_Sales.
Contoh 20.14.
Dengan batasan CHECK. Menggunakan perintah ALTER TABLE, Anda dapat menambahkan batasan pada kolom "Tanggal penjualan" (tanggal_tanggal) setiap tabel sehingga barisnya sesuai dengan salah satu kuartal dalam setahun. Tampilan penjualan kemudian dibuat memungkinkan untuk mengakses tabel ini, baik satu atau semua bersama-sama.
ALTER TABLE Q1_Sales ADD CONSTRAINT C0 CHECK (s_date ANTARA "jan-1-2002" DAN "mar-31-2002"); ALTER TABLE Q2_Sales ADD CONSTRAINT C1 CHECK (s_date ANTARA "Apr 1-2002" DAN "Jun-30-2002"); ALTER TABLE Q3_Sales ADD CONSTRAINT C2 check (s_date ANTARA "jul-1-2002" DAN "sep-30-2002"); ALTER TABLE Q4_Sales ADD CONSTRAINT C3 check (s_date ANTARA "oct-1-2002" DAN "dec-31-2002"); BUAT VIEW sales_v SEBAGAI PILIH * FROM Q1_Sales UNION SEMUA PILIH * FROM Q2_Sales UNION SEMUA PILIH * FROM Q3_Sales UNION SEMUA PILIH * FROM Q4_Sales;
Keuntungan seperti itu lihat partisi adalah bahwa predikat batasan CHECK tidak dievaluasi untuk setiap baris kueri. Predikat tersebut mengecualikan penyisipan ke dalam tabel baris yang tidak sesuai dengan kriteria predikat. Baris yang cocok dengan predikat pembagian diambil dari database lebih cepat.
Contoh 20.15.
Mempartisi Tampilan menggunakan klausa WHERE. Mari buat tampilan untuk tabel yang sama seperti pada contoh di atas.
BUAT VIEW sales_v SEBAGAI PILIH * FROM Q1_Sales WHERE s_date ANTARA "jan-1-2002" DAN "mar-31-2002" UNION ALL SELECT * FROM Q2_Sales WHERE s_date ANTARA "apr-1-2002" DAN "jun-30-2002" UNION ALL SELECT * FROM Q3_Sales WHERE s_date ANTARA "jul-1-2002" DAN "sep-30-2002" UNION ALL SELECT * FROM Q4_Sales WHERE s_date ANTARA "oct-1-2002" DAN "dec-31-2002";
metode lihat partisi menggunakan klausa WHERE memiliki beberapa kelemahan. Pertama, kriteria pembagian diperiksa pada saat dijalankan untuk semua baris di semua partisi yang dicakup oleh kueri. Kedua, pengguna mungkin salah memasukkan baris ke bagian yang salah, mis. masukkan baris yang terkait dengan kuartal pertama ke kuartal ketiga, yang akan mengakibatkan pengambilan sampel data yang salah untuk kuartal tersebut.
Teknik ini memiliki keunggulan dibandingkan menggunakan kendala CHECK. Dimungkinkan untuk meng-host partisi yang cocok dengan klausa WHERE pada database jarak jauh. Sebuah fragmen dari definisi penyerahan diberikan di bawah ini.
Saat memutuskan untuk membuat, Anda perlu mengingat faktor-faktor berikut.
- dan menghapus data, bekerja di tingkat partisi, bukan seluruh tabel yang mendasarinya.
- Akses ke salah satu bagian tidak berpengaruh pada data di bagian lain.
- Oracle DBMS memiliki kemampuan bawaan yang diperlukan untuk mengenali tampilan yang dipartisi.
- Mempartisi Tampilan sangat berguna saat bekerja dengan tabel yang berisi sejumlah besar data historis.
Tabel partisi dalam DBMS dari keluarga MS SQL Server
Buat Tabel yang Dipartisi
DBMS dari keluarga MS SQL Server juga mendukung pembagian tabel, indeks, dan tampilan. Namun, tidak seperti Oracle DBMS, pembagian dalam DBMS dari keluarga MS SQL Server, dijalankan sesuai dengan skema terpadu.
Di MS SQL Server, semua tabel dan indeks dalam database dianggap terpartisi, meskipun hanya terdiri dari satu partisi. Faktanya, partisi adalah unit organisasi dasar dalam arsitektur fisik tabel dan indeks. Ini berarti bahwa arsitektur logis dan fisik dari tabel dan indeks yang mencakup banyak partisi sepenuhnya mencerminkan arsitektur tabel dan indeks yang terdiri dari satu partisi.
Pemotongan tabel dan indeks diatur keras di tingkat baris ( pembagian oleh kolom tidak diperbolehkan) dan memungkinkan akses melalui satu titik masuk (nama tabel atau nama indeks) sedemikian rupa sehingga kode aplikasi tidak perlu mengetahui jumlah partisi. Pemotongan dapat dilakukan pada tabel dasar, serta pada indeks yang terkait dengannya.
Setiap area nilai di bagian memiliki batas, yang didefinisikan dalam pernyataan FOR VALUES. Jika tanggal penjualannya adalah 23 Juni 2006, maka baris tersebut akan disimpan di bagian 2 (P2).
Sekarang mari kita buat skema pembagian. Skema pembagian memetakan partisi ke grup file yang berbeda (bernama MyFilegroup1, MyFilegroup2, MyFilegroup3, MyFilegroup4), seperti yang ditunjukkan pada perintah berikut:
BUAT SKEMA PARTISI MyPartitionScheme SEBAGAI MyPartitionFunction TO (MyFilegroup1, MyFilegroup2, MyFilegroup3, MyFilegroup4)
MyPartitionScheme adalah namanya skema pembagian, dan nama MyPartitionFunction mendefinisikan fungsi pembagian. Perintah ini menampilkan data dalam partisi yang terkait dengan satu atau lebih grup file. Baris dengan data dengan nilai kolom "Tanggal penjualan" (Date_of_Event date) sebelum 1/01/05 dikaitkan dengan MyFilegroup1 . Baris dalam kolom ini dengan nilai lebih besar atau sama dengan 1/01/05 dan hingga 1/01/07 ditetapkan ke MyFilegroup2 . Baris dengan nilai lebih besar atau sama dengan 1/01/07 dan sebelum 1/01/09 dikaitkan dengan MyFilegroup3 . Semua baris lain dengan nilai lebih besar atau sama dengan 1/01/09 dikaitkan dengan MyFilegroup4 .
Untuk setiap set nilai batas (yang ditentukan oleh FOR VALUES fungsi pembagian) jumlah bagian akan sama dengan "Jumlah nilai batas" + 1 bagian. Klausa CREATE PARTITION SCHEME sebelumnya mencakup tiga batasan dan empat partisi. Terlepas dari apakah partisi dibuat dengan RANGE RIGHT atau RANGE LEFT , jumlah partisi akan selalu "Jumlah Nilai Batas" + 1, hingga 1000 partisi per tabel.
Sekarang kita bisa membuat tabel yang dipartisi fakta PENJUALAN. Penciptaan tabel yang dipartisi tidak jauh berbeda dengan membuat tabel biasa, anda hanya perlu mengacu pada namanya saja skema pembagian dalam kondisi ON, seperti yang ditunjukkan pada perintah di bawah ini.
BUAT TABEL PENJUALAN (identitas bigint Sales_SHV (1, 1) primer tidak berkerumun NOT NULL, Cust_ID bigint null, Prod_ID bigint null, Store_ID bigint null, REG_ID char(10) null, Time_of_Event time null, Kuantitas integer bukan null, Jumlah dec(8 ,2) bukan null, Date_of_Event date NOT NULL) DI MyPartitionScheme(Date_of_Event)
Mendefinisikan nama skema pembagian, desainer menentukan bahwa tabel ini adalah indeks . Hal ini memungkinkan perancang untuk merancang struktur indeks berdasarkan data yang dipartisi daripada seluruh data tabel. Membuat indeks yang dipartisi memerlukan pembuatan b-tree terpisah pada indeks yang dipartisi. Memisahkan indeks menciptakan indeks yang lebih kecil, dan administrator basis data atau DW menjadi lebih mudah dirawat saat mengubah, menambah, dan menghapus data.
Saat membuat indeks yang dipartisi, Anda dapat membuat selaras atau indeks yang tidak selaras. Indeks yang disejajarkan menyiratkan hubungan langsung ke data tabel yang dipartisi. Dalam kasus indeks yang tidak selaras, indeks yang berbeda dipilih skema pembagian.
Dari dua metode, indeks selaras lebih disukai, yang dipilih secara default jika, setelah pembuatan tabel yang dipartisi indeks dibuat tanpa menentukan yang lain skema pembagian. Penggunaan indeks selaras memberikan fleksibilitas yang diperlukan untuk membuat bagian tambahan di tabel, dan juga memungkinkan Anda untuk mentransfer kepemilikan bagian tertentu ke tabel lain. Untuk memecahkan sebagian besar masalah yang terkait dengan pembagian, cukup untuk mengajukan indeks skema pembagian tabel.
Contoh. 20.19.
Mari kita buat partisi indeks tidak berkerumun pada dipartisi tabel "Penjualan" (SALES) dari contoh sebelumnya 20.18.
BUAT SKEMA PARTISI Index_primary_Left_Scheme SEBAGAI PARTISI Index_Left_Partition ALL TO ()
Sekarang mari kita jalankan perintah create index seperti yang ditunjukkan di bawah ini.
BUAT INDEKS NONCLUTERED cl_multiple_partition PADA multiple_partition(Cust_ID) PADA Index_primary_Left_Scheme(Cust_ID)
Karena indeks nonclustered kolom "ID Pelanggan" (Cust_ID) digunakan sebagai kunci indeks, yang bukan kunci partisi tabel "Penjualan" (SALES).
Keputusan tentang partisi indeks diterima oleh perancang data warehouse pada tahap desain atau oleh administrator data warehouse pada tahap pengoperasian data warehouse. tujuan partisi indeks adalah untuk memastikan kinerja kueri atau untuk menyederhanakan prosedur pemeliharaan indeks.
Anda dapat membuat tabel atau indeks yang dipartisi di SQL Server 2016 menggunakan SQL Server Management Studio atau Transact-SQL. Data dalam tabel dan indeks yang dipartisi secara horizontal dibagi menjadi blok-blok yang dapat tersebar di beberapa grup file dalam database. Partisi dapat meningkatkan pengelolaan dan skalabilitas tabel dan indeks besar.
Atau indeks biasanya mencakup empat tahap:
Buat grup file atau grup file dan file terkait yang akan berisi partisi sesuai dengan skema partisi.
Buat fungsi partisi yang memetakan tabel atau baris indeks ke partisi berdasarkan nilai elemen kolom tertentu.
Buat skema partisi yang memetakan partisi tabel atau indeks yang dipartisi ke grup file baru.
Buat atau ubah tabel atau indeks dan tentukan skema partisi sebagai lokasi penyimpanan.
Di bagian ini
Sebelum Anda mulai, selesaikan langkah-langkah berikut.
Pembatasan
Keamanan
Buat tabel atau indeks yang dipartisi menggunakan alat berikut:
Studio Manajemen SQL Server
Pembatasan
Ruang lingkup skema fungsi dan partisi terbatas pada basis data tempat ia dibuat. Fungsi partisi berada di namespace yang terpisah dari fungsi lain dalam database.
Jika ada baris dalam fungsi partisi yang memiliki kolom partisi nol, baris tersebut ditempatkan di partisi paling kiri. Namun, jika null ditetapkan sebagai nilai batas dan opsi KANAN ditentukan, partisi paling kiri dibiarkan kosong dan nilai null ditempatkan di partisi kedua.
Keamanan
Izin
Membuat tabel yang dipartisi memerlukan izin CREATE TABLE pada database dan izin ALTER pada skema di mana tabel dibuat. Membuat indeks yang dipartisi memerlukan izin ALTER pada tabel atau tampilan di mana indeks sedang dibuat. Membuat tabel atau indeks yang dipartisi memerlukan salah satu izin tambahan berikut:
MENGUBAH izin DATASPACE APAPUN. Izin ini ditetapkan secara default ke anggota peran server tetap sysadmin dan peran basis data yang telah ditentukan sebelumnya db_owner dan db_ddladmin.
CONTROL atau ALTER izin pada database di mana fungsi dan skema partisi dibuat.
MENGONTROL SERVER atau MENGUBAH izin DATABASE APAPUN di server database tempat skema fungsi dan partisi dibuat.
Menyelesaikan petunjuk langkah demi langkah dalam prosedur ini untuk membuat satu atau lebih grup file, file terkait, dan tabel. Dalam contoh berikut, referensi ke objek ini akan diberikan saat membuat tabel yang dipartisi.
Membuat Filegroup Baru untuk Tabel yang Dipartisi
Buat Tabel yang Dipartisi
Di kotak dialog Buat jadwal kerja di lapangan Nama masukkan nama untuk jadwal pekerjaan.
Terdaftar Jenis Jadwal pilih jenis jadwal:
Mulai secara otomatis ketika SQL Server Agent dimulai
Jalankan saat prosesor menganggur
berulang. Pilih opsi ini jika tabel yang dipartisi baru diperbarui secara berkala dengan data baru.
satu kali. Opsi ini dipilih secara default.
Dalam bab Frekuensi dalam daftar dilakukan tentukan frekuensi eksekusi:
Saat memilih Harian di lapangan Berjalan setiap Tentukan seberapa sering tugas dijadwalkan untuk dijalankan lagi dalam beberapa hari.
Saat memilih Mingguan di lapangan Berjalan setiap Tentukan seberapa sering pekerjaan dijadwal ulang dalam beberapa minggu. Pilih hari atau hari dalam seminggu di mana jadwal pekerjaan berjalan.
Saat memilih Bulanan klik Hari atau Pasti.
Saat memilih Hari masukkan tanggal bulan di mana jadwal pekerjaan harus dijalankan, dan tentukan seberapa sering jadwal pekerjaan dijalankan lagi dalam beberapa bulan. Misalnya, jika Anda ingin jadwal pekerjaan berjalan pada tanggal 15 setiap bulan kedua, pilih Hari dan masukkan "15" di bidang pertama dan "2" di bidang kedua. Harap dicatat bahwa nomor yang dimasukkan di kolom kedua tidak boleh melebihi "99".
Saat memilih Pasti pilih hari tertentu dalam seminggu di bulan di mana Anda ingin jadwal pekerjaan dijalankan, dan tentukan seberapa sering jadwal pekerjaan dijalankan lagi dalam beberapa bulan. Misalnya, jika Anda ingin jadwal pekerjaan berjalan pada hari terakhir setiap minggu setiap bulan kedua, pilih Hari, Pilih terakhir dalam daftar pertama dan hari kerja di daftar kedua, lalu masukkan "2" di bidang kedua. Anda juga dapat memilih pertama, kedua, ketiga atau keempat, serta hari-hari tertentu dalam seminggu (misalnya, Minggu atau Rabu) di dua daftar pertama. Harap dicatat bahwa nomor yang dimasukkan di kolom terakhir tidak boleh melebihi "99".
Saat memilih Jalankan sekali per tentukan waktu tertentu dalam sehari untuk menjalankan jadwal pekerjaan di lapangan Jalankan sekali per. Tentukan waktu hari: jam, menit dan detik.
Saat memilih Berjalan setiap tentukan frekuensi pelaksanaan tugas pada hari yang dipilih di lapangan Frekuensi. Misalnya, jika Anda ingin jadwal pekerjaan berjalan setiap 2 jam pada hari jadwal pekerjaan dimulai, pilih Berjalan setiap., masukkan "2" di bidang pertama, lalu pilih dari daftar jam tangan. Anda juga dapat memilih dari daftar ini menit dan detik. Harap dicatat bahwa angka yang dimasukkan di kolom pertama tidak boleh melebihi "100".
di lapangan Dimulai dari masukkan waktu untuk memulai jadwal pekerjaan untuk dijalankan. di lapangan berakhir pada masukkan waktu untuk menyelesaikan penjadwalan ulang pekerjaan. Tentukan waktu hari: jam, menit dan detik.
Klik kanan tabel untuk mempartisi, pilih Penyimpanan dan klik Buat bagian...
PADA Penyihir Bagian Di halaman Selamat datang di Bagian Wizard klik Lebih jauh.
Di halaman Pemilihan kolom partisi di kisi, pilih kolom yang ingin Anda gunakan untuk mempartisi tabel. di kisi-kisi Kolom partisi yang tersedia hanya kolom dengan tipe data yang dapat dipartisi yang ditampilkan. Jika Anda memilih kolom yang dihitung sebagai kolom partisi, Anda harus menjadikannya permanen.
Pilihan kolom partisi dan rentang nilai ditentukan terutama oleh sejauh mana data harus dikelompokkan secara logis. Misalnya, Anda dapat membagi data ke dalam grup logis menurut bulan atau kuartal dalam setahun. Kueri data terjadwal menentukan apakah pengelompokan logis tersebut memadai untuk mengelola partisi tabel. Semua jenis data dapat digunakan sebagai kolom partisi, kecuali teks, ntext, gambar, xml, stempel waktu, varchar (maks), nvarchar(maks), varbinary (maks), alias tipe data, dan tipe data yang ditentukan pengguna CLR.
Colocation tabel ini dengan tabel dipartisi yang dipilih
Memungkinkan Anda memilih tabel yang dipartisi yang berisi data terkait untuk digabungkan dengan tabel ini dengan mempartisi kolom. Tabel yang dipartisi yang digabungkan dengan kolom yang dipartisi umumnya lebih efisien dalam kueri.
Sejajarkan penyimpanan indeks non-unik dan unik dengan kolom partisi yang diindeks
Menyelaraskan semua indeks pada tabel yang dipartisi menggunakan skema yang sama. Dengan menyelaraskan tabel dan indeksnya, partisi dapat lebih efisien dipindahkan masuk dan keluar dari tabel yang dipartisi karena data dipartisi menggunakan algoritma yang sama.
Setelah memilih kolom partisi dan kolom lainnya, klik Lebih jauh.
Di halaman Pemilihan fungsi partisi Dalam bab Pilih fungsi pembagian klik atau . Saat memilih Buat fungsi pembagian masukkan nama fungsi. Jika opsi dipilih Fungsi Partisi yang Ada, lalu pilih nama fungsi yang akan digunakan untuk mempartisi dari daftar. Perhatikan bahwa jika tidak ada fungsi partisi lain dalam database, Fungsi Partisi yang Ada akan tidak tersedia.
Lebih jauh.
Di halaman Memilih Skema Partisi Dalam bab Pilih skema partisi klik atau . Saat memilih Buat skema partisi masukkan nama skema. Jika opsi dipilih Skema partisi yang ada, lalu pilih nama skema yang akan digunakan dari daftar. Jika tidak ada skema partisi lain dalam database, parameter Skema partisi yang ada akan tidak tersedia.
Setelah menyelesaikan halaman ini, klik tombol Lebih jauh.
Di halaman Pemetaan Partisi Dalam bab Jangkauan Pilih Batas kiri atau Batas kanan untuk memilih nilai batas terbesar atau terkecil untuk disertakan dalam semua grup file yang dibuat. Selain jumlah grup file yang ditentukan sebagai nilai batas saat membuat partisi, Anda harus selalu memasukkan satu grup file tambahan.
di kisi-kisi Memilih Filegroups dan Menentukan Nilai Batas di lapangan Grup file pilih grup file tempat data akan dipartisi. Dalam bab Pinggiran masukkan nilai batas untuk setiap grup file. Jika tidak ada nilai batas yang ditentukan, fungsi partisi memetakan seluruh tabel atau indeks ke satu partisi menggunakan nama fungsi partisi.
Opsi tambahan berikut tersedia di halaman ini:
Tetapkan batas...
Membuka kotak dialog Menetapkan nilai batas, di mana Anda dapat memilih titik henti sementara dan rentang tanggal untuk partisi. Opsi ini hanya tersedia jika Anda memilih kolom partisi yang berisi salah satu tipe data berikut ini: tanggal, tanggal Waktu, tanggal kecil, datetime2 atau datetimeoffset.
Peringkat penyimpanan
Perkiraan jumlah baris, ruang penyimpanan yang diperlukan dan tersedia untuk setiap grup file yang ditentukan untuk partisi. Nilai-nilai ini hanya-baca di kisi.
Di kotak dialog Menetapkan nilai batas Anda dapat mengatur opsi tambahan berikut:
tanggal awal
Pilih tanggal mulai untuk nilai rentang partisi.
tanggal habis tempo
Pilih tanggal akhir untuk nilai rentang partisi. Saat memilih Batas kiri Di halaman Pemetaan Partisi tanggal ini akan menjadi nilai terakhir untuk setiap grup file dan partisi. Saat memilih Batas kanan Di halaman Pemetaan Partisi tanggal ini akan menjadi nilai pertama dalam filegroup kedua dari belakang.
rentang tanggal
Pilih langkah perincian tanggal atau nilai rentang untuk setiap bagian.
Setelah menyelesaikan halaman ini, klik tombol Lebih jauh.
Di halaman Memilih parameter keluaran tentukan cara mengisi tabel yang dipartisi. Pilih Buat skrip untuk membuat skrip SQL berdasarkan data di halaman wizard sebelumnya. Pilih Jalankan segera untuk membuat tabel terpartisi baru setelah Anda menyelesaikan semua halaman wizard yang tersisa. Pilih Jadwal untuk membuat tabel partisi baru terlebih dahulu waktu yang diberikan di masa depan.
Saat memilih Buat skrip di Parameter skrip pilihan berikut akan tersedia:
Keluarkan skrip ke file
Membuat skrip sebagai file SQL. Masukkan nama dan lokasi file di kolom Nama file atau klik Tinjauan untuk membuka dialog Lokasi file skrip. Dalam bab Simpan sebagai Pilih Teks dalam Unicode atau teks ANSI.
Keluarkan skrip ke papan klip
Menyimpan skrip ke clipboard.
Tampilkan skrip di jendela kueri baru
Script dibuat di jendela editor kueri baru. Opsi ini dipilih secara default.
Saat memilih Jadwal klik Ubah jadwal.
Centang atau hapus centang Termasuk untuk mengaktifkan atau menonaktifkan jadwal.
Saat memilih berulang:
di lapangan Berapa kali sehari? tentukan seberapa sering jadwal pekerjaan akan dieksekusi ulang pada hari jadwal pekerjaan dimulai:
Dalam bab Durasi, di daerah tanggal awal masukkan tanggal mulai untuk jadwal pekerjaan yang akan dijalankan. Pilih tanggal habis tempo atau Tidak ada tanggal akhir untuk menentukan tanggal akhir untuk pelaksanaan jadwal pekerjaan. Saat memilih tanggal habis tempo masukkan tanggal akhir untuk jadwal pekerjaan yang akan dijalankan.
Saat memilih nilai satu kali di Eksekusi tunggal di lapangan tanggal masukkan tanggal mulai untuk jadwal pekerjaan. di lapangan Waktu masukkan waktu mulai untuk jadwal pekerjaan. Tentukan waktu hari: jam, menit dan detik.
Dalam bab Ringkasan di Keterangan Verifikasi bahwa semua pengaturan penjadwalan pekerjaan sudah benar.
Klik tombol Oke.
Setelah menyelesaikan halaman ini, klik tombol Lebih jauh.
Di halaman Melihat Ringkasan Dalam bab Lihat opsi yang dipilih Perluas semua opsi yang tersedia untuk memastikan semua pengaturan bagian sudah benar. Jika semua pengaturan sudah benar, tekan tombol Siap.
Halaman Pertunjukan Wizard Buat Partisi digunakan untuk melacak informasi status tentang tindakan Wizard Buat Partisi. Bergantung pada tindakan yang dipilih dalam panduan, halaman kemajuan dapat berisi satu atau beberapa tindakan. Kotak atas menunjukkan keadaan umum wizard dan jumlah status, peringatan, dan pesan kesalahan yang diterimanya.
Di halaman Pertunjukan Wizard pembuatan bagian memiliki opsi berikut:
Intelijen
Informasi tentang acara, status, dan pesan apa pun yang dikembalikan sebagai hasil dari tindakan wizard.
Tindakan
Menentukan jenis dan nama setiap tindakan.
Negara
Menunjukkan apakah tindakan wizard secara keseluruhan mengembalikan nilai Berhasil atau Kesalahan.
Pesan
Setiap kesalahan atau pesan peringatan dari proses.
Laporan
Buat laporan yang berisi hasil dari Partition Wizard. Pilihan yang tersedia: Melihat laporan, Simpan laporan ke file, dan Kirim laporan melalui email.
Melihat Laporan
Membuka kotak dialog Melihat Laporan, yang berisi laporan teks tentang pembuatan wizard partisi.
Salin laporan ke papan klip
Menyalin hasil laporan wizard ke clipboard.
Kirim laporan melalui email
Menyalin hasil laporan status wizard ke pesan email.
Setelah Anda selesai memilih opsi, tekan tombol menutup.
Wizard Buat Partisi akan membuat fungsi dan skema partisi, lalu menerapkan partisi ke tabel yang ditentukan. Untuk memeriksa partisi tabel, di Object Explorer, klik kanan tabel dan pilih Properti. Buka halaman penyimpanan. Halaman tersebut menampilkan informasi, termasuk nama fungsi partisi, skema, dan jumlah partisi.
Buat Tabel yang Dipartisi
PADA penjelajah objek terhubung ke sebuah instance dari Database Engine.
Pada panel standar, pilih Buat permintaan.
Salin contoh berikut ke dalam jendela kueri dan klik tombol Lari. Contoh berikut menunjukkan pembuatan grup file, fungsionalitas, dan skema partisi. Tabel baru dibuat saat Anda menentukan skema partisi sebagai lokasi penyimpanan.
GUNAKAN AdventureWorks2012; PERGILAH -- Menambahkan empat grup file baru ke database AdventureWorks2012 ALTER DATABASE AdventureWorks2012 ADD FILEGROUP test1fg; PERGILAH ALTER DATABASE AdventureWorks2012 TAMBAHKAN FILEGROUP test2fg; PERGILAH ALTER DATABASE AdventureWorks2012 TAMBAHKAN FILEGROUP test3fg; PERGILAH ALTER DATABASE AdventureWorks2012 TAMBAHKAN FILEGROUP test4fg; -- Menambahkan satu file untuk setiap grup file. ALTER DATABASE AdventureWorks2012 TAMBAHKAN FILE(NAME=test1dat1, FILENAME= "C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\DATA\t1dat1.ndf", UKURAN = 5 MB, MAXSIZE = 100 MB, FILEGROWTH = 5 MB) KE FILEGROUP test1fg; ALTER DATABASE AdventureWorks2012 TAMBAHKAN FILE(NAME=test2dat2, FILENAME= "C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\DATA\t2dat2.ndf", UKURAN = 5 MB, MAXSIZE = 100 MB, FILEGROWTH = 5 MB) KE FILEGROUP test2fg; PERGILAH ALTER DATABASE AdventureWorks2012 TAMBAHKAN FILE(NAME=test3dat3, FILENAME= "C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\DATA\t3dat3.ndf", UKURAN = 5 MB, MAXSIZE = 100 MB, FILEGROWTH = 5 MB) KE FILEGROUP test3fg; PERGILAH ALTER DATABASE AdventureWorks2012 TAMBAHKAN FILE(NAME=test4dat4, FILENAME= "C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\DATA\t4dat4.ndf", UKURAN = 5 MB, MAXSIZE = 100 MB, FILEGROWTH = 5 MB) KE FILEGROUP test4fg; PERGILAH -- Membuat fungsi partisi yang disebut myRangePF1 yang akan mempartisi tabel menjadi empat partisi BUAT FUNGSI PARTISI myRangePF1 (int ) SEBAGAI RANGE KIRI UNTUK NILAI (1 , 100 , 1000 ); PERGILAH -- Membuat skema partisi bernama myRangePS1 yang menerapkan myRangePF1 ke empat grup file yang dibuat di atas BUAT SKEMA PARTISI myRangePS1 SEBAGAI PARTISI myRangePF1 TO (test1fg, test2fg, test3fg, test4fg); PERGILAH -- Membuat tabel terpartisi bernama PartitionTable yang menggunakan myRangePS1 untuk mempartisi col1 CREATE TABLE PartitionTable (col1 int PRIMARY KEY , col2 char (10 )) PADA myRangePS1 (col1) ; PERGILAH
Mendefinisikan partisi tabel
Kueri berikut mengembalikan satu atau beberapa baris jika PartitionTable dipartisi. Jika tabel tidak dipartisi, tidak ada baris yang dikembalikan.
Menentukan Nilai Batas untuk Tabel yang Dipartisi
Kueri berikut mengembalikan nilai batas untuk setiap partisi di PartitionTable.
SELECT t .name AS TableName, i .name AS IndexName, p .partition_number, p .partition_id, i .data_space_id, f .function_id, f .type_desc, r.boundary_id, r.value AS BoundaryValue FROM sys .tablessy AS JOIN .indexes AS i ON t .object_id = i .object_id GABUNG sys .partitions AS p ON i .object_id = p .object_id AND i .index_id = p .index_id GABUNG sys .partition_schemes AS sydata_space i . .partition_functions AS f ON s.function_id = f .function_id KIRI GABUNG sys .partition_range_values AS r ON f .function_id = r.function_id dan r.boundary_id = p .partition_number WHERE t .name = "PartitionTable" DAN i .<= 1 ORDER BY p .partition_number;
Mendefinisikan Kolom Partisi dari Tabel yang Dipartisi
Kueri berikut mengembalikan nama kolom partisi tabel. Tabel Partisi.
PILIH t . AS ObjectID , t .name AS TableName , ic.column_id AS PartitioningColumnID , c .name AS PartitioningColumnName FROM sys .tables AS t JOIN sys .indexes AS i ON t . = saya. Dan saya .<= 1 -- clustered index or a heap JOIN sys .partition_schemes AS ps ON ps.data_space_id = i .data_space_id JOIN sys .index_columns AS ic ON ic. = i . AND ic.index_id = i .index_id AND ic.partition_ordinal >= 1 -- karena 0 = kolom non-partisi GABUNG sys .columns SEBAGAI c ON t . = c. AND ic.column_id = c .column_id WHERE t .name = "PartitionTable" ; PERGILAH
Untuk informasi lebih lanjut, lihat.
Selama bekerja pada tabel besar, kami terus-menerus menghadapi masalah dengan kinerja pemeliharaan dan pembaruan data. Partisi adalah salah satu solusi paling produktif dan nyaman untuk masalah yang muncul.
Secara umum, partisi adalah mempartisi tabel atau indeks menjadi blok-blok. Tergantung pada pengaturan partisi, blok dapat memiliki ukuran yang berbeda dan dapat disimpan dalam filegroup dan file yang berbeda.
Partisi memiliki kelebihan dan kekurangan.
Manfaatnya dijelaskan dengan baik di situs web Microsoft, berikut kutipannya:
« Mempartisi tabel atau indeks besar dapat memberikan manfaat pengelolaan dan kinerja berikut.
- Hal ini memungkinkan subset data untuk ditransfer dan diakses dengan cepat dan efisien dengan tetap menjaga integritas dataset. Misalnya, operasi seperti memuat data dari OLTP ke sistem OLAP membutuhkan waktu beberapa detik, bukan menit dan jam seperti halnya data yang tidak dipartisi.
- Operasi pemeliharaan dapat dilakukan lebih cepat dengan satu atau lebih bagian. Operasi lebih efisien karena hanya dilakukan pada subset data daripada seluruh tabel. Misalnya, Anda dapat mengompresi data ke dalam satu atau beberapa partisi, atau membangun kembali satu atau beberapa partisi indeks.
- Anda dapat meningkatkan kinerja kueri berdasarkan kueri yang sering dijalankan pada konfigurasi perangkat keras Anda. Misalnya, pengoptimal kueri dapat melakukan kueri gabungan-sama antara dua atau lebih tabel yang dipartisi lebih cepat jika tabel tersebut memiliki kolom partisi yang sama, karena partisi itu sendiri dapat digabungkan.
Saat menyortir data untuk operasi I/O di SQL Server, data diurutkan berdasarkan partisi terlebih dahulu. SQL Server hanya dapat mengakses satu disk pada satu waktu, yang dapat menurunkan kinerja. Untuk mempercepat penyortiran data, disarankan untuk mendistribusikan file data dalam beberapa bagian di beberapa hard drive dengan membuat RAID. Jadi, meskipun mengurutkan data berdasarkan partisi, SQL Server akan dapat mengakses semua hard drive di setiap partisi secara bersamaan.
Anda juga dapat meningkatkan kinerja dengan menerapkan kunci pada tingkat partisi daripada seluruh tabel. Ini dapat mengurangi jumlah konflik kunci untuk tabel».
Kerugiannya termasuk kesulitan dalam mengelola dan memelihara operasi tabel yang dipartisi.
Kami tidak akan membahas implementasi partisi, karena masalah ini dijelaskan dengan sangat baik di situs web Microsoft.
Sebagai gantinya, kami akan mencoba menunjukkan cara untuk mengoptimalkan pengoperasian tabel yang dipartisi, atau lebih tepatnya, kami akan menunjukkan cara yang optimal (menurut pendapat kami) untuk memperbarui data untuk periode waktu apa pun.
Keuntungan besar dari tabel yang dipartisi adalah pemisahan fisik dari partisi ini. Properti ini memungkinkan kita untuk menukar bagian antara mereka sendiri atau dengan tabel lainnya.
Dalam pembaruan data normal menggunakan jendela geser (misalnya, selama sebulan), kita harus melalui langkah-langkah berikut:
1. Temukan baris yang diperlukan dalam tabel besar;
2. Hapus baris yang ditemukan dari tabel dan indeks;
3. Masukkan baris baru ke dalam tabel, perbarui indeks.
Saat menyimpan miliaran baris dalam sebuah tabel, operasi ini akan memakan waktu yang cukup lama, tetapi kita dapat membatasi diri kita pada hampir satu tindakan: cukup ganti bagian yang diinginkan dengan tabel (atau bagian) yang disiapkan sebelumnya. Dalam hal ini, kita tidak perlu menghapus atau menyisipkan baris, dan kita juga perlu memperbarui indeks di seluruh tabel besar.
Mari beralih dari kata ke perbuatan dan tunjukkan bagaimana menerapkannya.
1. Pertama, siapkan tabel yang dipartisi seperti yang dijelaskan dalam artikel yang disebutkan di atas.
2. Kami membuat tabel yang diperlukan untuk pertukaran.
Untuk memperbarui data, kita memerlukan salinan mini dari tabel target. Ini adalah salinan mini karena akan menyimpan data yang harus ditambahkan ke tabel target, mis. data hanya 1 bulan. Anda juga akan membutuhkan tabel kosong ketiga untuk mengimplementasikan pertukaran data. Mengapa itu diperlukan - saya akan menjelaskannya nanti.
Ketentuan ketat ditetapkan untuk salinan mini dan meja untuk pertukaran:
- Kedua tabel harus ada sebelum menggunakan pernyataan SWITCH. Sebelum operasi switch dapat dilakukan, baik tabel dari mana partisi sedang dipindahkan (tabel sumber) dan tabel yang menerima partisi (tabel target) harus ada dalam database.
- Bagian tujuan harus ada dan harus kosong. Jika sebuah tabel ditambahkan sebagai partisi ke tabel yang telah dipartisi yang sudah ada, atau jika sebuah partisi dipindahkan dari satu tabel yang dipartisi ke tabel lainnya, maka partisi tujuan harus ada dan kosong.
- Tabel tujuan yang tidak dipartisi harus ada dan harus kosong. Jika partisi dimaksudkan untuk membentuk tabel tunggal yang tidak dipartisi, maka tabel yang menerima partisi baru harus ada dan merupakan tabel kosong yang tidak dipartisi.
- Bagian harus dari kolom yang sama. Jika sebuah partisi dipindahkan dari satu tabel yang dipartisi ke tabel yang lain, maka kedua tabel tersebut harus dipartisi pada kolom yang sama.
- Tabel sumber dan target harus berada dalam grup file yang sama. Tabel sumber dan target dalam pernyataan ALTER TABLE...SWITCH harus disimpan dalam filegroup yang sama, serta kolom nilainya yang besar. Setiap indeks yang relevan, partisi indeks, atau tampilan partisi yang diindeks juga harus disimpan pada grup file yang sama. Namun, mungkin berbeda dari filegroup untuk masing-masing tabel atau indeks lain yang relevan.
Mari saya jelaskan batasannya dengan contoh kita:
1. Thumbnail tabel harus dipartisi pada kolom yang sama dengan target. Jika thumbnail bukan tabel yang dipartisi, maka harus disimpan pada filegroup yang sama dengan partisi yang diganti.
2. Tabel pertukaran harus kosong dan juga harus dipartisi pada kolom yang sama atau disimpan pada filegroup yang sama.
3. Kami menerapkan pertukaran.
Sekarang kita memiliki yang berikut:
Tabel dengan data untuk semua waktu (selanjutnya Table_A)
Tabel dengan data selama 1 bulan (selanjutnya Tabel_B)
Tabel kosong (selanjutnya Table_C)
Pertama-tama, kita perlu mencari tahu di bagian mana kita menyimpan data.
Anda dapat mengetahuinya dengan bertanya:
PILIH
dihitung sebagai
, $PARTITION.(dt) sebagai
, rank() lebih (urutkan berdasarkan $PARTITION.(dt))
DARI dbo. (tidak terkunci)
kelompokkan menurut $PARTITION.(dt)
Dalam kueri ini, kami mendapatkan bagian yang memiliki deretan informasi. Jumlahnya tidak dapat dihitung - kami melakukan ini untuk memeriksa kebutuhan pertukaran data. Kami menggunakan Rank sehingga kami dapat mengulang dan memperbarui beberapa bagian dalam satu prosedur.
Segera setelah kami mengetahui di bagian mana kami menyimpan data, mereka dapat ditukar. Katakanlah data disimpan di partisi 1.
Maka Anda perlu melakukan operasi berikut:
Tukar partisi dari tabel target dengan tabel untuk ditukar.
ALTER TABEL. BERALIH PARTISI 1 KE . PARTISI 1
Sekarang kita memiliki yang berikut:
Tidak ada data yang tersisa di tabel target di bagian yang kita butuhkan, mis. bagian kosong
Tukar partisi dari tabel target dan thumbnail
ALTER TABEL. BERALIH PARTISI 1 KE . PARTISI 1
Sekarang kita memiliki yang berikut:
Data bulanan muncul di tabel target, dan salinan mini sekarang kosong
Hapus atau hapus tabel untuk ditukar.
Jika Anda memiliki indeks berkerumun di atas meja, maka ini juga tidak menjadi masalah. Itu harus dibuat pada semua 3 tabel yang dipartisi pada kolom yang sama. Saat mengubah partisi, indeks akan diperbarui secara otomatis tanpa membangun kembali.
Dalam artikel ini, saya akan mendemonstrasikan secara spesifik rencana eksekusi kueri saat mengakses tabel yang dipartisi. Perhatikan bahwa ada perbedaan besar antara tabel yang dipartisi (yang hanya tersedia dengan SQL Server 2005) dan tampilan yang dipartisi (yang tersedia di SQL Server 2000, dan masih tersedia di SQL Server 2005 dan yang lebih baru). Saya akan mendemonstrasikan fitur rencana kueri untuk tampilan yang dipartisi di artikel lain.
Tampilan meja
Mari kita buat tabel partisi sederhana:
buat fungsi partisi pf(int) sebagai rentang untuk nilai (0, 10, 100)
buat skema partisi ps sebagai partisi pf semua ke ()
buat tabel t (a int, b int) di ps(a)
Script ini membuat tabel dengan empat partisi. SQL Server menetapkan nilai ke ID masing-masing dari empat partisi seperti yang ditunjukkan pada tabel:
| PtnId | nilai-nilai |
| 1 | t.a<= 0 |
| 2 | 0 < t.a <= 10 |
| 3 | 10 < t.a <= 100 |
| 4 | 100 < t.a |
Sekarang mari kita lihat rencana kueri yang akan memaksa pengoptimal untuk menggunakan Pemindaian Tabel:
……|–Pemindaian Konstan(NILAI:(((1)),((2)),((3)),((4))))
…….|–Pemindaian Tabel(OBJEK:([t]))
Dalam rencana di atas, SQL Server secara eksplisit menentukan semua ID partisi dalam pernyataan "Pemindaian Konstan" yang mengimplementasikan pemindaian tabel dan memasok data ke pernyataan bergabung loop bersarang. Ingat di sini bahwa pernyataan join loop bersarang berulang melalui tabel bagian dalam (dalam hal ini, pemindaian tabel penuh) satu kali untuk setiap nilai dari tabel luar (dalam kasus kami, "Pemindaian Konstan"). Jadi, kami memindai tabel empat kali; sekali untuk setiap ID bagian.
Perlu juga dicatat bahwa loop bersarang bergabung secara eksplisit menunjukkan bahwa tabel luar adalah nilai kolom tempat ID partisi disimpan. Meskipun tidak segera terlihat dalam tampilan teks rencana eksekusi (sayangnya, terkadang kami tidak melihat informasi ini), pemindaian tabel menggunakan kolom dengan ID partisi yang dipilih untuk melakukan pemindaian dan menentukan partisi mana yang akan dipindai. Informasi ini selalu tersedia dalam rencana eksekusi grafis (Anda perlu melihat properti operator tampilan tabel), serta dalam representasi XML dari rencana eksekusi kueri:
Penyaringan Bagian Statis
Pertimbangkan kueri berikut:
pilih * dari t di mana a< 100
|–Loop Bersarang(Gabung Dalam, REFERENSI LUAR:() ID PARTISI:())
…….|–Pemindaian Konstan(NILAI:(((1)),((2)),((3))))
<(100)) PARTITION ID:())
Predikat "a<100» явно исключает все строки для секции со значением идентификатора равным 4. В данном случае, нет смысла в просмотре соответствующей секции, поскольку ни одна из строк этой секции не удовлетворяет условию предиката. Оптимизатор учитывает этот факт и исключает эту секцию из плана исполнения запроса. В операторе «Constant Scan» указаны только три секции. У нас принято называть это статической фильтрацией секций (static partition elimination), поскольку мы знаем, что во время компиляции список просматриваемых секций остаётся статичным.
Jika semua bagian kecuali satu dikecualikan sebagai akibat dari pemfilteran statis, kami tidak memerlukan operator "Pemindaian Konstan" dan "Loop Bersarang Bergabung" sama sekali:
pilih * dari t di mana a< 0
|–Pemindaian Tabel(OBJEK:([t]), DIMANA:([t].[a]<(0)) PARTITION ID:((1)))
Perhatikan bahwa petunjuk "PARTITION ID:((1))", yang menentukan ID partisi yang akan dipindai, sekarang menjadi bagian dari pernyataan Table Scan.
Pemfilteran bagian dinamis
Dalam beberapa kasus, SQL Server tidak dapat menentukan bahwa partisi yang dilihatnya tidak akan berubah pada waktu kompilasi, tetapi dapat melihat bahwa beberapa partisi dapat dikecualikan.
pilih * dari t di mana a< @i
|–Loop Bersarang(Gabung Dalam, REFERENSI LUAR:() ID PARTISI:())
…….|–Filter(DIMANA :(<=RangePartitionNew([@i],(0),(0),(10),(100))))
…….| |–Pemindaian Konstan(NILAI:(((1)),((2)),((3)),((4))))
…….|–Pemindaian Tabel(OBJEK:([t]), DIMANA:([t].[a]<[@i]) PARTITION ID:())
Ini adalah kueri berparameter. Karena kita tidak mengetahui nilai parameter sebelum eksekusi (fakta bahwa saya menggunakan konstanta sebagai parameter dalam batch yang sama tidak mengubah situasi), tidak mungkin untuk menentukan nilai pengidentifikasi bagian untuk "Pemindaian Konstan ” operator pada tahap kompilasi. Anda mungkin hanya perlu melihat bagian 1, atau bagian 1 dan 2, dan seterusnya. Oleh karena itu, keempat pengidentifikasi bagian ditentukan dalam pernyataan ini, dan kami menggunakan pemfilteran pengidentifikasi bagian pada waktu proses. Kami menyebutnya Penghapusan Partisi Dinamis.
Filter membandingkan setiap pengenal partisi dengan hasil fungsi khusus "RangePartitionNew". Fungsi ini menghitung hasil penerapan fungsi sectioning ke nilai parameter. Argumen untuk fungsi ini (dari kiri ke kanan) adalah:
- nilai (dalam hal ini parameter @i) yang ingin kita petakan ke ID bagian;
- boolean yang menunjukkan apakah fungsi partisi menampilkan nilai batas di kiri (0) atau kanan (1);
- nilai batas bagian (dalam hal ini, 0, 10, dan 100).
Dalam contoh ini, karena @i adalah 0, hasil "RangePartitionNew" adalah 1. Jadi, kami hanya memindai partisi dengan ID 1. Perhatikan bahwa, tidak seperti contoh penyaringan partisi statis, meskipun kami hanya memindai satu partisi, kami masih memiliki "Pemindaian Konstan" dan "Loop Bersarang Bergabung". Kami membutuhkan pernyataan ini karena kami tidak tahu bagian yang akan dipindai sampai tahap eksekusi.
Dalam beberapa kasus, pengoptimal sudah dapat menentukan pada waktu kompilasi bahwa kami hanya akan memindai satu bagian, meskipun tidak dapat menentukan yang mana. Misalnya, jika kueri menggunakan predikat kesetaraan kunci partisi, maka kita tahu bahwa hanya satu partisi yang dapat memenuhi kondisi tersebut. Oleh karena itu, terlepas dari kenyataan bahwa kita seharusnya memiliki pemfilteran partisi dinamis, kita tidak memerlukan pernyataan "Constant Scan" dan "Nested Loops Join". Contoh:
pilih * dari t di mana a = @i
|–Pemindaian Tabel(OBJEK:([t]), DIMANA:([t].[a]=[@i]) ID PARTISI:(RangePartitionNew([@i],(0),(0),(10 ),(100)))))
Kombinasi penyaringan partisi statis dan dinamis
SQL Server dapat menggabungkan pemfilteran partisi statis dan dinamis dalam paket kueri yang sama:
pilih * dari t di mana a > 0 dan a< @i
|–Loop Bersarang(Gabung Dalam, REFERENSI LUAR:() ID PARTISI:())
……|–Filter(DIMANA :(<=RangePartitionNew([@i],(0),(0),(10),(100))))
……| |–Pemindaian Konstan(NILAI:(((2)),((3)),((4))))
……|–Pemindaian Tabel(OBJEK:([t]), DIMANA:([t].[a]<[@i] AND [t].[a]>(0)) ID PARTISI:())
Perhatikan bahwa dalam rencana terakhir, ada pemfilteran statis pada partisi ID = 1 menggunakan "Pemindaian Konstan", dan ada juga pemfilteran dinamis untuk partisi lain yang ditentukan oleh predikat.
$partisi
Anda dapat secara eksplisit memanggil fungsi RangePartitionNew menggunakan $partition:
pilih *, $partition.pf(a) dari t
|–Menghitung Skalar(DEFINE:(=RangePartitionNew([t].[a],(0),(0),(10),(100))))
……|–Loop Bersarang(Gabung Dalam, REFERENSI LUAR:() ID PARTISI:())
………..|–Pemindaian Konstan(NILAI:(((1)),((2)),((3)),((4))))
………..|–Pemindaian Tabel(OBJEK:([t]))
Fitur khas dari rencana eksekusi kueri semacam itu adalah penampilan operator Compute Scalar.
informasi tambahan