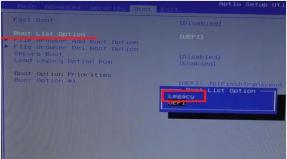
Jaringan saraf dalam contoh statistik. STATISTICA Jaringan Saraf Otomatis (Jaringan Saraf Otomatis). Neural networks STATISTICA Neural Networks: Metodologi dan teknologi analisis data modern
Apa persamaan dan perbedaan antara bahasa neurocomputing dan statistik dalam analisis data. Mari kita pertimbangkan contoh paling sederhana.
Mari kita asumsikan bahwa kita memiliki pengamatan dan diukur secara eksperimental N pasang titik yang mewakili ketergantungan fungsional. Jika kita mencoba menggambar garis lurus terbaik melalui titik-titik ini, yang dalam bahasa statistik berarti menggunakan ketergantungan yang tidak diketahui untuk menggambarkan model linier
(di mana menunjukkan kebisingan selama pengamatan), maka solusi untuk masalah yang sesuai regresi linier mengurangi untuk menemukan nilai taksiran parameter yang meminimalkan jumlah kuadrat residu.
Jika parameter dan ditemukan, maka kita dapat memperkirakan nilainya kamu untuk nilai berapa pun x, yaitu untuk melaksanakan interpolasi dan ekstrapolasi data.
Masalah yang sama dapat diselesaikan dengan menggunakan jaringan lapisan tunggal dengan satu input dan satu linier neuron keluaran. Berat komunikasi sebuah dan ambang batas b dapat diperoleh dengan meminimalkan jumlah residu yang sama (yang dalam hal ini akan disebut akar rata-rata kuadrat) kesalahan) selama sedang belajar jaringan, misalnya, menggunakan metode backpropagation. Properti jaringan saraf untuk generalisasi selanjutnya akan digunakan untuk memprediksi nilai keluaran dari nilai masukan.
Gambar 25. Regresi linier dan perceptron satu lapis yang mengimplementasikannya.
Ketika membandingkan kedua pendekatan ini, langsung mengejutkan bahwa ketika menggambarkan metode mereka, statistik menarik untuk rumus dan persamaan, dan neurocomputing untuk deskripsi grafis arsitektur saraf.
1 Jika kita ingat bahwa belahan kiri beroperasi dengan rumus dan persamaan, dan belahan kanan beroperasi dengan gambar grafik, maka kita dapat memahaminya dibandingkan dengan statistik, “ belahan kanan”pendekatan jaringan saraf.
Perbedaan signifikan lainnya adalah bahwa untuk metode statistik tidak masalah bagaimana perbedaan akan diminimalkan - dalam hal apa pun model tetap sama, sedangkan untuk neurocomputing peran utama dimainkan oleh metode mengajar. Dengan kata lain, berbeda dengan pendekatan neural network, estimasi parameter model untuk metode statistik tidak bergantung pada metode minimisasi. Pada saat yang sama, ahli statistik akan mempertimbangkan perubahan dalam bentuk residual, katakanlah dengan
bagaimana perubahan model mendasar.
Berbeda dengan pendekatan jaringan saraf, di mana waktu utama diambil oleh pelatihan jaringan, dengan pendekatan statistik, waktu ini dihabiskan untuk analisis masalah secara menyeluruh. Pada saat yang sama, pengalaman ahli statistik digunakan untuk memilih model berdasarkan analisis data dan informasi yang spesifik untuk area tertentu. Penggunaan jaringan saraf - pendekatan universal ini - biasanya dilakukan tanpa menggunakan pengetahuan apriori, meskipun dalam beberapa kasus sangat berguna. Misalnya, untuk model linier yang sedang dipertimbangkan, penggunaan kesalahan akar rata-rata kuadrat mengarah untuk memperoleh estimasi parameter yang optimal ketika nilai noise memiliki distribusi normal dengan varians yang sama untuk semua pasangan pelatihan. Pada saat yang sama, jika diketahui bahwa varians ini berbeda, maka gunakan tertimbang fungsi kesalahan
dapat memberikan nilai parameter yang jauh lebih baik.
Selain model paling sederhana yang dipertimbangkan, contoh lain, dalam arti tertentu, model statistik dan paradigma jaringan saraf yang setara dapat diberikan.
Tabel 3. Metode serupa
Jaringan Hopfield memiliki hubungan yang jelas dengan pengelompokan data dan analisis faktor.
1 Analisis faktor digunakan untuk belajar struktur data. Premis utamanya adalah asumsi keberadaan tanda-tanda seperti itu - faktor, yang tidak dapat diamati secara langsung, tetapi dapat diperkirakan dari beberapa fitur utama yang dapat diamati. Misalnya, tanda-tanda seperti volume produksi dan nilai aset tetap, dapat menentukan faktor seperti skala produksi. Tidak seperti jaringan saraf yang membutuhkan pelatihan, analisis faktor hanya dapat bekerja dengan sejumlah pengamatan tertentu. Meskipun pada prinsipnya jumlah pengamatan tersebut seharusnya hanya satu lebih besar dari jumlah variabel, disarankan untuk menggunakan setidaknya tiga kali lebih banyak nilai. Ini masih dianggap kurang dari ukuran set pelatihan untuk jaringan saraf. Oleh karena itu, ahli statistik menunjukkan keuntungan dari analisis faktor dalam menggunakan lebih sedikit data dan oleh karena itu menghasilkan generasi model yang lebih cepat. Selain itu, ini berarti bahwa penerapan metode analisis faktor membutuhkan kurang kuat fasilitas komputasi. Keuntungan lain dari analisis faktor adalah metode kotak putih, yaitu. benar-benar terbuka dan dapat dimengerti - pengguna dapat dengan mudah memahami mengapa model memberikan hasil tertentu. Hubungan analisis faktor dengan model Hopfield dapat dilihat dengan mengingat vektor basis minimum untuk satu set pengamatan (gambar memori - lihat Bab 5). Vektor-vektor inilah yang merupakan analog dari faktor-faktor yang menyatukan berbagai komponen vektor memori - fitur utama.
1 Regresi logistik adalah metode klasifikasi biner yang banyak digunakan dalam pengambilan keputusan keuangan. Ini memungkinkan untuk memperkirakan probabilitas realisasi (atau non-realisasi) dari beberapa peristiwa tergantung pada nilai beberapa variabel independen - prediktor: x 1 ,...,x N . Dalam model regresi logistik, probabilitas ini memiliki bentuk analitik: Pr( X) =(1+exp(-z)) -1 , di mana z = a 0 + a 1 x 1 +...+ a N x N . Mitra jaringan sarafnya, jelas, adalah perceptron lapisan tunggal dengan neuron keluaran nonlinier. Dalam aplikasi keuangan, regresi logistik lebih disukai daripada regresi linier multivariat dan analisis diskriminan karena sejumlah alasan. Secara khusus, secara otomatis memastikan bahwa probabilitas milik interval , memberlakukan lebih sedikit batasan pada distribusi nilai prediktor. Yang terakhir ini sangat signifikan, karena distribusi nilai indikator keuangan yang berbentuk rasio biasanya tidak normal dan “sangat miring”. Keuntungan dari jaringan saraf adalah bahwa situasi ini tidak menjadi masalah bagi mereka. Selain itu, jaringan saraf tidak sensitif terhadap korelasi nilai prediktor, sedangkan metode untuk memperkirakan parameter model regresi dalam hal ini sering memberikan nilai yang tidak akurat.
R adalah lingkungan perangkat lunak gratis untuk komputasi statistik dan grafik.
Ini adalah proyek GNU yang mirip dengan bahasa dan lingkungan S yang dikembangkan di Bell Laboratories (sebelumnya AT&T, sekarang Lucent Technologies) oleh John Chambers dan rekan-rekannya. R dapat dianggap sebagai implementasi yang berbeda dari S. Ada beberapa perbedaan penting, tetapi sebagian besar kode yang ditulis untuk S berjalan tidak berubah di bawah R.
Sumber terbuka gratis Mac Windows Linux BSD
RStudio
RStudio™ adalah lingkungan pengembangan terintegrasi (IDE) untuk bahasa pemrograman R. RStudio menggabungkan antarmuka pengguna yang intuitif dengan alat pengkodean yang kuat untuk membantu Anda mendapatkan hasil maksimal dari R.
Sumber terbuka gratis Mac Windows Linux Xfce
PSPP
PSPP gratis aplikasi perangkat lunak untuk analisis data sampel. Ini memiliki antarmuka pengguna grafis dan antarmuka konvensional garis komando. Itu ditulis dalam C, menggunakan perpustakaan ilmiah GNU untuk rutinitas matematikanya, dan plotutils untuk pembuatan grafik. Hal ini dimaksudkan untuk menjadi pengganti gratis untuk program SPSS berpemilik.
Sumber terbuka gratis Mac Windows Linux
Statistik IBM SPSS
Platform perangkat lunak IBM SPSS menawarkan analisis statistik tingkat lanjut, perpustakaan kaya algoritme pembelajaran mesin, analisis teks, ekstensibilitas sumber terbuka, integrasi data besar, dan penerapan aplikasi tanpa batas.
Dibayar Mac Windows Linux
Statistik SOFA
SOFA Statistics adalah paket statistik open source yang berfokus pada kemudahan penggunaan, pembelajaran sambil jalan, dan hasil yang luar biasa. Nama singkatan dari "Statistik terbuka untuk semua". Ini memiliki antarmuka pengguna grafis dan dapat terhubung langsung ke MySQL, SQLite, MS Access dan MS SQL Server
Sumber terbuka gratis Mac Windows Linux
Apa yang ada di daftar ini?
Daftar ini berisi program yang dapat digunakan untuk menggantikan STATISTICA dengan Platform Windows. Daftar ini berisi 6 aplikasi yang mirip dengan STATISTICA.
Saya memutuskan untuk menyentuh topik yang luas. Jaringan saraf tiruan. Saya akan mencoba untuk memberikan ide pada jari. Apa itu? Ini adalah upaya untuk mensimulasikan otak manusia. Hanya lebih primitif. Elemen dasar dari setiap jaringan saraf adalah neuron (Gbr. 1).
Beras. satu. diagram sirkuit saraf.
Neuron memiliki input, penambah dan fungsi aktivasi. Informasi dipasok ke input, misalnya, isi tiga kimia. elemen dalam sampel tertentu. Masing-masing dikalikan dengan koefisien tertentu. Selanjutnya, sinyal yang masuk dijumlahkan dan dikonversi menggunakan fungsi aktivasi. Bisa jadi tangen nomor yang diberikan, atau e^(-1*jumlah tertentu), di mana e adalah bilangan Euler. Seluruh tsim terdiri dari:
Timbangan neuron;
Fungsi aktivasi;
Satu set neuron. Jika Anda mengambil beberapa neuron dan mengaturnya menjadi beberapa lapisan, yang masing-masing akan memiliki dari 1 hingga N neuron, maka ini akan menjadi jaringan saraf tiruan.
Jaringan syaraf tiruan perlu dilatih, atau diberi kesempatan untuk belajar sendiri. Melatih jaringan saraf berarti memberikan sampel dan menyesuaikan bobot sehingga neuron menggambarkan data seakurat mungkin. Fungsi aktivasi hanya memodelkan hubungan kimia nonlinier. elemen. Dan struktur jaringan saraf (jumlah neuron, jumlah lapisan) mengontrol fleksibilitas jaringan. Itu adalah seberapa akurat itu dapat menyesuaikan dengan data. Pada saat yang sama, penyesuaian yang benar-benar tepat tidak diperlukan dalam geokimia. Penting untuk mengidentifikasi pola.
Ketika kita tahu sedikit tentang data, clustering digunakan. Dalam kasus jaringan saraf, jaringan saraf belajar mandiri Kohonen digunakan. Arti mereka terletak pada kenyataan bahwa neuron, seperti pada Gambar 1, disusun menjadi satu lapisan dua dimensi (Gbr. 2). Neuron pertama secara acak diberikan bobot primer dan pengamatan dimasukkan. Neuron bersaing di antara mereka sendiri untuk deskripsi terbaik dari pengamatan. Pemenang mencoba menipu tetangga mereka. Pada akhirnya, ketika ada cluster nyata dalam data, mereka akan dijelaskan oleh kelompok neuron yang berbeda. Pesona, kan?

Beras. 2. Diagram skema Jaringan Pengorganisasian Diri Kohonen. 4x3 neuron = 12 neuron.
 Beras. 3. Buka data dan jalankan modul analisis jaringan saraf. Data dapat digunakan mentah, tanpa pra-logaritma. Tetapi emisi eksplisit masih lebih baik untuk dihilangkan.
Beras. 3. Buka data dan jalankan modul analisis jaringan saraf. Data dapat digunakan mentah, tanpa pra-logaritma. Tetapi emisi eksplisit masih lebih baik untuk dihilangkan.
 Beras. 4 Memilih analisis klaster
Beras. 4 Memilih analisis klaster
 Beras. 5. Pilih variabel di tab Cepat. Dalam modul ini, Anda dapat memilih variabel input kategoris. Misalnya, umur batuan tempat sampel diambil.
Beras. 5. Pilih variabel di tab Cepat. Dalam modul ini, Anda dapat memilih variabel input kategoris. Misalnya, umur batuan tempat sampel diambil.
 Beras. 6 Buka tab kedua Sampling (Subsamples). Jaringan syaraf tiruan memecah sampel awal menjadi tiga sub-sampel:
Beras. 6 Buka tab kedua Sampling (Subsamples). Jaringan syaraf tiruan memecah sampel awal menjadi tiga sub-sampel:
Pendidikan. Ini digunakan untuk melatih jaringan saraf dan menyesuaikan bobot;
Uji. Ini juga digunakan dalam proses pembelajaran dan memeriksa apakah jaringan telah dilatih ulang;
sampel uji. Ini tidak digunakan dalam proses pelatihan, tetapi hanya berfungsi untuk mengevaluasi keakuratan jaringan pada data "baru". Artinya, kemampuannya untuk memprediksi.
Mari kita biarkan secara default. Klik Oke.
 Beras. 7 Di tab Cepat (Kohonen), atur jumlah neuron dan strukturnya. Karena neuron mengajar tetangga mereka, lokasi neuron juga penting. Atau atur 4 neuron dalam bujur sangkar, atau dalam rantai. Sebagai permulaan, pilih 5x5. Jangan berusaha untuk membuat jaringan besar. Ingatlah bahwa penting untuk mengidentifikasi pola umum, dan tidak menyelesaikan semuanya sekaligus.
Beras. 7 Di tab Cepat (Kohonen), atur jumlah neuron dan strukturnya. Karena neuron mengajar tetangga mereka, lokasi neuron juga penting. Atau atur 4 neuron dalam bujur sangkar, atau dalam rantai. Sebagai permulaan, pilih 5x5. Jangan berusaha untuk membuat jaringan besar. Ingatlah bahwa penting untuk mengidentifikasi pola umum, dan tidak menyelesaikan semuanya sekaligus.
 Beras. Di tab Pelatihan Kohonen, paling banyak parameter penting Lingkungan - berapa banyak tetangga yang dilatih neuron. Mari kita biarkan secara default. Klik Oke.
Beras. Di tab Pelatihan Kohonen, paling banyak parameter penting Lingkungan - berapa banyak tetangga yang dilatih neuron. Mari kita biarkan secara default. Klik Oke.
 Beras. 9. Jaringan dilatih dan jendela hasil ditampilkan. Langsung ke tab Kohonen (grafik). Ini menunjukkan semua 25 neuron dan berapa banyak sampel pelatihan yang masuk ke masing-masing. Dianggap perlu bahwa setiap neuron menggambarkan beberapa bagian dari data. Seharusnya tidak ada neuron kosong. Puncak yang diwakili oleh warna merah coklat menunjukkan berapa banyak sampel yang menggambarkan neuron ini. Secara umum, ada tiga puncak. Kemungkinan besar kita memiliki tiga cluster. Klik Batal, Batal dan buka tab pertama untuk memilih struktur jaringan.
Beras. 9. Jaringan dilatih dan jendela hasil ditampilkan. Langsung ke tab Kohonen (grafik). Ini menunjukkan semua 25 neuron dan berapa banyak sampel pelatihan yang masuk ke masing-masing. Dianggap perlu bahwa setiap neuron menggambarkan beberapa bagian dari data. Seharusnya tidak ada neuron kosong. Puncak yang diwakili oleh warna merah coklat menunjukkan berapa banyak sampel yang menggambarkan neuron ini. Secara umum, ada tiga puncak. Kemungkinan besar kita memiliki tiga cluster. Klik Batal, Batal dan buka tab pertama untuk memilih struktur jaringan.
 Beras. 10. Kami memilih rantai neuron dari tiga bagian. Setiap neuron akan menggambarkan clusternya.
Beras. 10. Kami memilih rantai neuron dari tiga bagian. Setiap neuron akan menggambarkan clusternya.
 Beras. 11. Buka tab Pelatihan Jaringan dan pilih bahwa setiap neuron hanya mempengaruhi satu tetangga. Cluster yang terhubung akan muncul. Layak untuk bereksperimen di sini. Jika pengaruhnya ada pada tetangga, maka kecil kemungkinan Anda akan dapat menangkap daerah transisi.
Beras. 11. Buka tab Pelatihan Jaringan dan pilih bahwa setiap neuron hanya mempengaruhi satu tetangga. Cluster yang terhubung akan muncul. Layak untuk bereksperimen di sini. Jika pengaruhnya ada pada tetangga, maka kecil kemungkinan Anda akan dapat menangkap daerah transisi.
 Beras. 12. Kami mendapatkan hasilnya. Setiap neuron menggambarkan cukup banyak data.
Beras. 12. Kami mendapatkan hasilnya. Setiap neuron menggambarkan cukup banyak data.
 Beras. 13. Mari kita pergi ke tab pertama dari jendela hasil Prediksi (Prediksi). Mari kita tampilkan hasil untuk setiap sampel dengan koordinat.
Beras. 13. Mari kita pergi ke tab pertama dari jendela hasil Prediksi (Prediksi). Mari kita tampilkan hasil untuk setiap sampel dengan koordinat.
 Beras. 14. Kami mendapatkan pelat keluaran. Untuk membuat grafik dari data di dalamnya, Anda perlu mengaktifkan pelat. Sorot, klik kanan dan pilih masukan aktif(Masukan Aktif). Di sini, seperti pada metode k-means, ada kolom dengan “jarak” sampel ke cluster (neuron). Semakin rendah angkanya, semakin baik. Jika jumlahnya sangat tinggi, maka ini adalah outlier atau cluster yang benar-benar terpisah.
Beras. 14. Kami mendapatkan pelat keluaran. Untuk membuat grafik dari data di dalamnya, Anda perlu mengaktifkan pelat. Sorot, klik kanan dan pilih masukan aktif(Masukan Aktif). Di sini, seperti pada metode k-means, ada kolom dengan “jarak” sampel ke cluster (neuron). Semakin rendah angkanya, semakin baik. Jika jumlahnya sangat tinggi, maka ini adalah outlier atau cluster yang benar-benar terpisah.
 Beras. 15. Kami membangun peta cluster. Anda bisa tentang itu. Tentu saja, plot ini paling baik dibangun di ArcGIS atau Surfer. Buat deskripsi dengan mempertimbangkan geol.map. Sayangnya, saya tidak bisa menulis banyak tentangnya di sini. Tetapi saya hanya bisa mengatakan bahwa pengelompokan jaringan saraf menghasilkan hasil yang serupa dengan pengelompokan hierarkis dan k-means. Selanjutnya, Anda dapat membuat grafik tipe Box-with-whiskers dan memberikan kesimpulan tentang spesialisasi cluster. Karena saya mengelompokkan sampel ini untuk ketiga kalinya, saya tidak menyajikannya. Lihat postingan sebelumnya.
Beras. 15. Kami membangun peta cluster. Anda bisa tentang itu. Tentu saja, plot ini paling baik dibangun di ArcGIS atau Surfer. Buat deskripsi dengan mempertimbangkan geol.map. Sayangnya, saya tidak bisa menulis banyak tentangnya di sini. Tetapi saya hanya bisa mengatakan bahwa pengelompokan jaringan saraf menghasilkan hasil yang serupa dengan pengelompokan hierarkis dan k-means. Selanjutnya, Anda dapat membuat grafik tipe Box-with-whiskers dan memberikan kesimpulan tentang spesialisasi cluster. Karena saya mengelompokkan sampel ini untuk ketiga kalinya, saya tidak menyajikannya. Lihat postingan sebelumnya.
Selain itu, kami membuat peta nilai aktivasi. Nilai aktivasi hanya ada jumlah elemen yang ditransformasikan oleh fungsi non-linier.
 Beras. 16. Peta sebaran nilai aktivasi pengamatan. Di selatan area, sekelompok sampel dengan nilai aktivasi tinggi dibedakan. Layak untuk mempertimbangkannya secara terpisah dalam hal peta monoelemen dan parameter lainnya.
Beras. 16. Peta sebaran nilai aktivasi pengamatan. Di selatan area, sekelompok sampel dengan nilai aktivasi tinggi dibedakan. Layak untuk mempertimbangkannya secara terpisah dalam hal peta monoelemen dan parameter lainnya.
 Beras. 17. Kami menyimpan struktur jaringan saraf. Sehingga Anda selalu dapat kembali ke sana.
Beras. 17. Kami menyimpan struktur jaringan saraf. Sehingga Anda selalu dapat kembali ke sana.
 Beras. 18. Ketika modul analisis jaringan saraf diluncurkan, di sebelah kiri ada jendela di mana Anda dapat membuka jaringan saraf yang sudah dibuat. Misalnya, Anda telah mempelajari objek referensi, membuat jaringan saraf berdasarkan objek tersebut, dan ingin menjalankan sampel dari area lain melaluinya. Voila.
Beras. 18. Ketika modul analisis jaringan saraf diluncurkan, di sebelah kiri ada jendela di mana Anda dapat membuka jaringan saraf yang sudah dibuat. Misalnya, Anda telah mempelajari objek referensi, membuat jaringan saraf berdasarkan objek tersebut, dan ingin menjalankan sampel dari area lain melaluinya. Voila.
- khaykin Simon Neural Networks: Kursus Lengkap, edisi ke-2. : Per. dari bahasa Inggris. - M. : Williams Publishing House, 2006. - 1104 hal. : Saya akan. - Parale. dada. Bahasa inggris ISBN 5-8459-0890-6 (rus)
- Jaringan saraf. STATISTICA Neural Networks: Metodologi dan teknologi analisis data modern / Diedit oleh V.P. Borovikov. - Edisi ke-2, direvisi. dan tambahan - M.: saluran telepon- Telecom, 2008. - 292 hal., sakit. ISBN 978-5-9912-0015-8
Buku kedua berbeda dari modul di Statistica 10, tetapi akan berfungsi juga.
STATISTICA Automated Neural Networks adalah satu-satunya jaringan saraf di dunia perangkat lunak, sepenuhnya diterjemahkan ke dalam bahasa Rusia!
Metodologi jaringan saraf menjadi semakin luas di berbagai bidang kegiatan mulai dari penelitian mendasar hingga aplikasi praktis analisis data, bisnis, industri, dll.
adalah salah satu produk jaringan saraf tercanggih dan paling efisien di pasar. Ini menawarkan banyak manfaat unik dan fitur yang kaya. Misalnya, kemampuan unik dari alat pencarian jaringan saraf otomatis, , memungkinkan sistem untuk digunakan tidak hanya oleh para ahli di jaringan saraf, tetapi juga oleh pemula di bidang komputasi jaringan saraf.
Apa manfaat menggunakan ?
Pra dan pasca-pemrosesan termasuk pemilihan data, pengkodean nilai nominal, penskalaan, normalisasi, penghapusan data yang hilang dengan interpretasi untuk masalah klasifikasi, regresi dan deret waktu;
Kemudahan penggunaan yang luar biasa ditambah daya analitik yang tak tertandingi; misalnya, alat pencarian jaringan saraf otomatis yang tak tertandingi Jaringan Neural Otomatis (JST) akan memandu pengguna melalui semua tahap pembuatan berbagai jaringan saraf dan memilih yang terbaik (jika tidak, tugas ini diselesaikan dengan proses panjang "coba-coba" dan membutuhkan pengetahuan teori yang serius);
Algoritma pembelajaran jaringan yang paling canggih, dioptimalkan dan kuat (termasuk metode gradien konjugasi, algoritma Levenberg-Marquardt, BFGS, algoritma Kohonen); kontrol penuh atas semua parameter yang mempengaruhi kualitas jaringan, seperti fungsi aktivasi dan kesalahan, kompleksitas jaringan;
Dukungan untuk ansambel jaringan saraf dan arsitektur jaringan saraf dengan ukuran hampir tidak terbatas;
Kemampuan grafis dan statistik yang kaya yang memfasilitasi analisis eksplorasi interaktif;
Integrasi penuh dengan sistem STATISTIK; semua hasil, grafik, laporan, dll. dapat dimodifikasi lebih lanjut menggunakan alat grafis dan analitis yang kuat STATISTIK(misalnya, untuk menganalisis residu yang diprediksi, membuat laporan terperinci, dll.);
Integrasi penuh dengan alat otomatis yang kuat STATISTIK; merekam makro lengkap untuk analisis apa pun; membuat analisis dan aplikasi jaringan saraf Anda sendiri menggunakan STATISTIK Panggilan Visual Basic Jaringan Neural Otomatis STATISTICA dari aplikasi apa pun yang mendukung teknologi COM (misalnya, analisis jaringan saraf otomatis dalam spreadsheet MS Excel atau kombinasi dari beberapa aplikasi pengguna yang ditulis dalam C, C++, C#, Java, dll.).
- Pilihan arsitektur jaringan paling populer, termasuk Multilayer Perceptrons, Radial Basis Functions, dan Self Organizing Feature Maps.
- Ada alatnya Pencarian Jaringan Otomatis, yang memungkinkan Anda membangun berbagai arsitektur jaringan saraf secara otomatis dan menyesuaikan kompleksitasnya.
- Menyimpan jaringan saraf terbaik.
- Kemampuan opsional untuk menghasilkan Kode sumber dalam C, C++, C#, Java, PMML (Predictive Model Markup Language), yang dapat dengan mudah diintegrasikan ke dalam lingkungan eksternal untuk membuat aplikasi Anda sendiri.
Dukungan untuk berbagai jenis analisis statistik dan pembuatan model prediktif, termasuk regresi, klasifikasi, deret waktu dengan variabel dependen kontinu dan kategoris, analisis klaster untuk pengurangan dimensi dan visualisasi.
Mendukung pemuatan dan analisis beberapa model.
Generator kode
Generator kode Jaringan Neural Otomatis STATISTICA dapat menghasilkan kode sistem sumber model jaringan saraf di C, Java dan PMML (Predictive Model Markup Language). Pembuat kode adalah aplikasi tambahan ke sistem Jaringan Neural Otomatis STATISTICA, yang memungkinkan pengguna untuk menghasilkan file C atau Java dengan kode sumber model berdasarkan analisis jaringan saraf yang dilakukan dan mengintegrasikannya ke dalam model independen aplikasi eksternal.
Pembuat kode membutuhkan Jaringan Neural Otomatis STATISTICA.
Menghasilkan versi kode sumber jaringan saraf (sebagai file C, C++, C#, atau Java).
File C atau Java dengan kode tersebut kemudian dapat disematkan ke dalam program eksternal.
STATISTIKotomatis Jaringan Saraf dalam komputasi jaringan saraf
Penggunaan jaringan saraf melibatkan lebih dari sekadar pemrosesan data menggunakan metode jaringan saraf.

STATISTICA Jaringan Saraf Otomatis (SANN) menyediakan berbagai Kegunaan, untuk bekerja dengan tugas yang sangat kompleks, termasuk tidak hanya yang terbaru Arsitektur Jaringan Saraf dan Belajar algoritma, tetapi juga pendekatan baru untuk membangun arsitektur jaringan saraf dengan kemampuan untuk menghitung berbagai fungsi aktivasi dan kesalahan, yang membuatnya lebih mudah untuk menginterpretasikan hasilnya. Selain itu, pengembang perangkat lunak dan pengguna yang bereksperimen dengan pengaturan aplikasi akan menghargai fakta bahwa setelah melakukan eksperimen yang diberikan dalam antarmuka yang sederhana dan intuitif STATISTICA Jaringan Saraf Otomatis (SANN), analisis jaringan saraf dapat digabungkan dalam aplikasi khusus. Ini dicapai baik dengan menggunakan perpustakaan fungsi COM STATISTIK, yang sepenuhnya mencerminkan semua fungsi program, atau menggunakan kode C / C ++ yang dihasilkan oleh program dan membantu menjalankan jaringan saraf yang sepenuhnya terlatih.
 Modul Jaringan Neural Otomatis STATISTICA terintegrasi penuh dengan sistem STATISTIK, sehingga banyak pilihan alat untuk mengedit (mempersiapkan) data untuk analisis (transformasi, kondisi untuk memilih pengamatan, alat validasi data, dll.) tersedia.
Modul Jaringan Neural Otomatis STATISTICA terintegrasi penuh dengan sistem STATISTIK, sehingga banyak pilihan alat untuk mengedit (mempersiapkan) data untuk analisis (transformasi, kondisi untuk memilih pengamatan, alat validasi data, dll.) tersedia.
Seperti semua analisis STATISTIK, program dapat "ditempelkan" ke basis data jarak jauh menggunakan alat pemrosesan di tempat atau ditautkan ke data langsung sehingga model dilatih atau dijalankan (misalnya, untuk menghitung nilai prediksi atau klasifikasi) secara otomatis setiap kali data berubah.
Penskalaan data dan konversi peringkat
Sebelum data dapat dimasukkan ke dalam jaringan, harus disiapkan dengan cara tertentu. Sama pentingnya bahwa output dapat diinterpretasikan dengan benar. PADA STATISTICA Jaringan Saraf Otomatis (SANN) ada kemungkinan penskalaan otomatis data input dan output; juga variabel dengan nilai nominal dapat dikodekan ulang secara otomatis (misalnya, Gender=(Pria,Wanita)), termasuk menggunakan metode pengkodean 1-of-N. STATISTICA Jaringan Saraf Otomatis (SANN) juga berisi alat untuk bekerja dengan data yang hilang. Ada alat persiapan dan interpretasi data yang dirancang khusus untuk analisis deret waktu. Berbagai cara serupa juga diterapkan di STATISTIK.
Dalam masalah klasifikasi, dimungkinkan untuk mengatur interval kepercayaan yang STATISTICA Jaringan Saraf Otomatis (SANN) kemudian digunakan untuk menetapkan pengamatan ke kelas tertentu. Dalam kombinasi dengan implementasi khusus di STATISTICA Jaringan Saraf Otomatis (SANN) Fungsi aktivasi Softmax dan fungsi kesalahan cross-entropy, ini memberikan pendekatan probabilistik mendasar untuk masalah klasifikasi.
Pilihan model jaringan saraf, ansambel jaringan saraf
Keragaman model jaringan saraf dan banyak parameter yang perlu diatur (ukuran jaringan, parameter algoritma pembelajaran, dll.) dapat membingungkan pengguna lain. Tapi untuk ini, ada alat pencarian jaringan saraf otomatis, , yang dapat secara otomatis mencari arsitektur jaringan yang sesuai dengan kompleksitas apa pun, lihat di bawah. Dalam sistem STATISTICA Jaringan Saraf Otomatis (SANN) semua jenis jaringan saraf utama yang digunakan dalam memecahkan masalah praktis telah diimplementasikan, termasuk: 
perceptron multilayer (jaringan dengan transmisi sinyal langsung);
jaringan pada fungsi basis radial;
peta Kohonen yang mengatur sendiri.
Arsitektur di atas digunakan dalam regresi, klasifikasi, deret waktu (dengan variabel dependen kontinu atau kategoris) dan masalah pengelompokan.
Selain itu, dalam sistem STATISTICA Jaringan Saraf Otomatis (SANN) dilaksanakan Ansambel Jaringan, dibentuk dari kombinasi acak (tetapi signifikan) dari jaringan di atas. Pendekatan ini sangat berguna untuk data yang bising dan berdimensi rendah.
Dalam paket STATISTICA Jaringan Saraf Otomatis (SANN) Banyak alat tersedia untuk membantu pengguna memilih arsitektur jaringan yang sesuai. Toolkit statistik dan grafis dari sistem mencakup histogram, matriks dan plot kesalahan untuk seluruh populasi dan untuk pengamatan individu, data akhir pada klasifikasi yang benar / salah, dan semua statistik penting, misalnya, proporsi varians yang dijelaskan, dihitung secara otomatis .
 Untuk memvisualisasikan data dalam batch STATISTICA Jaringan Saraf Otomatis (SANN) menerapkan scatterplots dan permukaan respons 3D untuk membantu pengguna memahami "perilaku" jaringan.
Untuk memvisualisasikan data dalam batch STATISTICA Jaringan Saraf Otomatis (SANN) menerapkan scatterplots dan permukaan respons 3D untuk membantu pengguna memahami "perilaku" jaringan.
Tentu saja, Anda dapat menggunakan informasi apa pun yang diperoleh dari sumber-sumber ini untuk analisis lebih lanjut dengan cara lain STATISTIK, serta untuk dimasukkan nanti dalam laporan atau untuk penyesuaian.
STATISTICA Jaringan Saraf Otomatis (SANN) secara otomatis mengingat versi jaringan terbaik dari yang Anda terima saat bereksperimen dengan tugas, dan Anda dapat merujuknya kapan saja. Kegunaan jaringan dan kemampuannya untuk memprediksi secara otomatis diuji pada serangkaian pengamatan pengujian khusus, serta dengan memperkirakan ukuran jaringan, efisiensinya, dan biaya kesalahan klasifikasi. Diimplementasikan dalam STATISTICA Jaringan Saraf Otomatis (SANN) validasi silang otomatis dan prosedur regularisasi bobot memungkinkan Anda mengetahui dengan cepat apakah jaringan Anda tidak mencukupi atau, sebaliknya, terlalu rumit untuk tugas tertentu.
Untuk meningkatkan kinerja dalam paket Jaringan Neural Otomatis STATISTICA Banyak pilihan konfigurasi jaringan disajikan. Jadi, Anda dapat menentukan lapisan jaringan keluaran linier dalam masalah regresi atau fungsi aktivasi softmax dalam estimasi probabilistik dan masalah klasifikasi. Sistem ini juga mengimplementasikan fungsi kesalahan lintas entropi berdasarkan model teori informasi dan seri fungsi khusus aktivasi, termasuk fungsi Identitas, Eksponensial, Hiperbolik, Logistik (sigmoid) dan Sinus untuk neuron tersembunyi dan neuron keluaran.
Jaringan saraf otomatis (pencarian otomatis dan pemilihan arsitektur jaringan saraf yang berbeda)
 Bagian dari paket STATISTICA Jaringan Saraf Otomatis (SANN) adalah alat pencarian jaringan saraf otomatis, Jaringan Neural Otomatis (JST) - Pencarian Jaringan Otomatis (ANS), yang mengevaluasi satu set jaringan saraf dari berbagai arsitektur dan kompleksitas dan memilih jaringan arsitektur terbaik untuk tugas yang diberikan.
Bagian dari paket STATISTICA Jaringan Saraf Otomatis (SANN) adalah alat pencarian jaringan saraf otomatis, Jaringan Neural Otomatis (JST) - Pencarian Jaringan Otomatis (ANS), yang mengevaluasi satu set jaringan saraf dari berbagai arsitektur dan kompleksitas dan memilih jaringan arsitektur terbaik untuk tugas yang diberikan.
 Banyak waktu saat membuat jaringan saraf dihabiskan untuk memilih variabel yang sesuai dan mengoptimalkan arsitektur jaringan menggunakan metode pencarian heuristik. STATISTICA Jaringan Saraf Otomatis (SANN) mengambil alih pekerjaan dan secara otomatis melakukan pencarian heuristik untuk Anda. Prosedur ini memperhitungkan dimensi input, jenis jaringan, ukuran jaringan, fungsi aktivasi, dan bahkan fungsi kesalahan output yang diperlukan.
Banyak waktu saat membuat jaringan saraf dihabiskan untuk memilih variabel yang sesuai dan mengoptimalkan arsitektur jaringan menggunakan metode pencarian heuristik. STATISTICA Jaringan Saraf Otomatis (SANN) mengambil alih pekerjaan dan secara otomatis melakukan pencarian heuristik untuk Anda. Prosedur ini memperhitungkan dimensi input, jenis jaringan, ukuran jaringan, fungsi aktivasi, dan bahkan fungsi kesalahan output yang diperlukan.
Ini adalah alat yang sangat efektif saat menggunakan teknik kompleks, memungkinkan Anda untuk secara otomatis menemukan arsitektur terbaik jaringan. Alih-alih menghabiskan berjam-jam duduk di depan komputer, berikan sistem STATISTICA Jaringan Saraf Otomatis (SANN) melakukan pekerjaan ini untuk Anda.
 Keberhasilan eksperimen Anda untuk menemukan jenis dan arsitektur jaringan terbaik sangat bergantung pada kualitas dan kecepatan algoritma pembelajaran jaringan. Dalam sistem STATISTICA Jaringan Saraf Otomatis (SANN) algoritma pelatihan terbaik sampai saat ini diimplementasikan.
Keberhasilan eksperimen Anda untuk menemukan jenis dan arsitektur jaringan terbaik sangat bergantung pada kualitas dan kecepatan algoritma pembelajaran jaringan. Dalam sistem STATISTICA Jaringan Saraf Otomatis (SANN) algoritma pelatihan terbaik sampai saat ini diimplementasikan.
Dalam sistem STATISTICA Jaringan Saraf Otomatis (SANN) dua algoritma orde kedua cepat diimplementasikan - metode gradien konjugasi dan algoritma BFGS. Yang terakhir adalah algoritma optimasi non-linear modern yang sangat kuat dan sangat direkomendasikan oleh para ahli. Ada juga versi sederhana dari algoritma BFGS yang membutuhkan lebih sedikit memori, yang digunakan oleh sistem jika memungkinkan memori akses acak komputer cukup terbatas. Algoritma ini cenderung untuk berkumpul lebih cepat dan menghasilkan solusi yang lebih akurat daripada algoritma akurasi orde pertama seperti Gradient Descent.
Proses pelatihan jaringan berulang dalam sistem STATISTICA Jaringan Saraf Otomatis (SANN) disertai dengan tampilan otomatis dari kesalahan pelatihan saat ini dan kesalahan yang dihitung secara independen pada set pengujian, dan grafik kesalahan total juga ditampilkan. Anda dapat berhenti belajar kapan saja hanya dengan menekan tombol. Selain itu, dimungkinkan untuk mengatur kondisi berhenti, setelah terpenuhinya pelatihan akan terganggu; kondisi seperti itu mungkin, misalnya, mencapai tingkat kesalahan tertentu, atau pertumbuhan yang stabil kesalahan verifikasi untuk nomor yang diberikan lewat - "zaman" (yang menunjukkan apa yang disebut pelatihan ulang jaringan). Jika overfitting terjadi, ini seharusnya tidak menjadi perhatian pengguna: STATISTICA Jaringan Saraf Otomatis (SANN) otomatis mengingat instance jaringan terbaik diperoleh selama proses pelatihan, dan versi jaringan ini selalu dapat diakses dengan menekan tombol yang sesuai. Setelah pelatihan jaringan selesai, Anda dapat memeriksa kualitas pekerjaannya pada set pengujian terpisah.
 Setelah jaringan dilatih, Anda perlu memeriksa kualitas pekerjaannya dan menentukan karakteristiknya. Untuk ini, paket STATISTICA Jaringan Saraf Otomatis (SANN) ada satu set statistik layar dan alat grafis.
Setelah jaringan dilatih, Anda perlu memeriksa kualitas pekerjaannya dan menentukan karakteristiknya. Untuk ini, paket STATISTICA Jaringan Saraf Otomatis (SANN) ada satu set statistik layar dan alat grafis.
Dalam hal beberapa model (jaringan dan ansambel) diberikan, maka (jika memungkinkan) STATISTICA Jaringan Saraf Otomatis (SANN) menampilkan hasil komparatif (misalnya, memplot kurva respons beberapa model pada grafik yang sama, atau menyajikan prediktor beberapa model dalam tabel yang sama). Properti ini sangat berguna untuk membandingkan model berbeda yang dilatih pada dataset yang sama.
 Semua statistik dihitung secara terpisah untuk set pelatihan, validasi, dan pengujian atau dalam kombinasi apa pun, atas kebijaksanaan pengguna.
Semua statistik dihitung secara terpisah untuk set pelatihan, validasi, dan pengujian atau dalam kombinasi apa pun, atas kebijaksanaan pengguna.
Ringkasan statistik berikut secara otomatis dihitung: kesalahan kuadrat rata-rata jaringan, apa yang disebut matriks kebingungan untuk masalah klasifikasi (di mana semua kasus klasifikasi yang benar dan salah dijumlahkan), dan korelasi untuk masalah regresi. Jaringan Kohonen memiliki jendela Peta Topologi di mana Anda dapat mengamati aktivasi elemen jaringan secara visual.
Solusi siap pakai (aplikasi khusus yang menggunakan Jaringan Neural Otomatis STATISTICA)
Antarmuka sistem yang sederhana dan ramah pengguna STATISTICA Jaringan Saraf Otomatis (SANN) memungkinkan Anda dengan cepat membuat aplikasi jaringan saraf untuk menyelesaikan masalah Anda.
 Mungkin ada situasi ketika perlu untuk mengintegrasikan solusi ini ke dalam sistem yang ada, misalnya, untuk menjadikannya bagian dari lingkungan komputasi yang lebih besar (ini mungkin prosedur yang dikembangkan secara terpisah dan dibangun ke dalam sistem komputasi perusahaan).
Mungkin ada situasi ketika perlu untuk mengintegrasikan solusi ini ke dalam sistem yang ada, misalnya, untuk menjadikannya bagian dari lingkungan komputasi yang lebih besar (ini mungkin prosedur yang dikembangkan secara terpisah dan dibangun ke dalam sistem komputasi perusahaan).
Jaringan saraf terlatih dapat diterapkan ke kumpulan data baru (untuk prediksi) dalam beberapa cara: Anda dapat menyimpan jaringan terlatih dan kemudian menerapkannya ke kumpulan data baru (untuk prediksi, klasifikasi, atau prediksi); Anda dapat menggunakan pembuat kode untuk pembuatan otomatis kode program dalam C (C++, C#) atau Visual Basic dan kemudian menggunakannya untuk memprediksi data baru di lingkungan perangkat lunak visual basic atau C++ (C#), yaitu mengimplementasikan jaringan saraf yang sepenuhnya terlatih dalam aplikasi Anda. Kesimpulannya, semua fungsi sistem STATISTIK, termasuk STATISTICA Jaringan Saraf Otomatis (SANN), dapat digunakan sebagai objek COM (Component Object Model) di aplikasi lain (mis. Java, MS Excel, C#, VB.NET, dll.). Misalnya, Anda dapat menerapkan analisis otomatis yang dibuat dengan STATISTICA Jaringan Saraf Otomatis (SANN) ke dalam spreadsheet MS Excel.
Daftar algoritma pembelajaran
penurunan gradien
Gradien konjugasi
Pelatihan Kohonen
Metode k-Means untuk Jaringan Fungsi Basis Radial
Batas ukuran jaringan
Jaringan saraf dapat berukuran hampir berapa pun (yaitu, dimensinya dapat diambil beberapa kali lebih besar daripada yang sebenarnya diperlukan dan masuk akal); untuk jaringan multilayer perceptrons, satu lapisan tersembunyi dari neuron diperbolehkan. Bahkan, untuk tugas praktis apa pun, program hanya dibatasi oleh kemampuan perangkat keras komputer.
manual elektronik
Sebagai bagian dari sistem STATISTICA Jaringan Saraf Otomatis (SANN) Ada buku teks yang diilustrasikan dengan baik yang memberikan pengantar yang lengkap dan dapat dipahami tentang jaringan saraf, serta contoh-contohnya. Dari kotak dialog mana pun, sistem bantuan sensitif konteks terperinci tersedia.
Pembuat Kode Sumber
Generator kode sumber adalah produk opsional yang memungkinkan pengguna dengan mudah membuat aplikasi mereka sendiri berdasarkan sistem STATISTICA Jaringan Saraf Otomatis (SANN). Produk tambahan ini menghasilkan kode sumber model jaringan saraf (sebagai file C, C++, C#, atau Java) yang dapat dikompilasi dan diintegrasikan secara terpisah ke dalam program Anda untuk distribusi gratis. Produk ini dirancang khusus untuk pengembang sistem korporat dan pengguna yang perlu mengonversi prosedur yang sangat dioptimalkan yang dibuat dalam STATISTICA Jaringan Saraf Otomatis (SANN), ke dalam aplikasi eksternal untuk memecahkan masalah analitis yang kompleks. (Perlu dicatat bahwa untuk mendapatkan izin, pengguna harus memberi tahu karyawan perusahaan situs tentang distribusi program menggunakan kode yang dihasilkan).